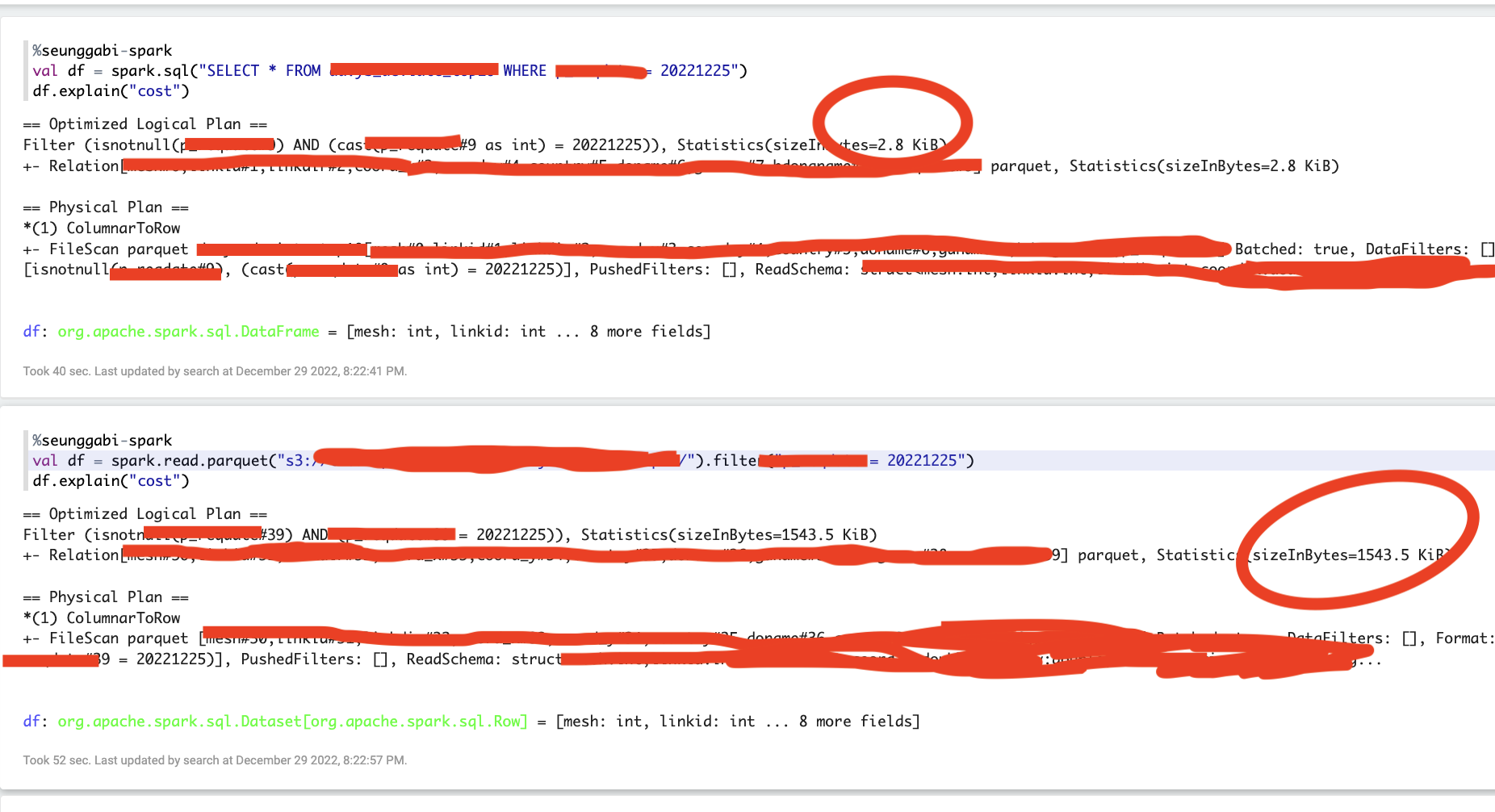
spark.read vs spark.sql - Why that is different cost..?
Boths have partition filtering.
But, spark.read(1543.5KiB; s3://a/b/c/target) speed is too slow.
And then more expensive than spark.sql(2.8KiB; s3://a/b/c/target/dt=20221225).
I think, this problem is spark.read to get partition columns.
- Listing leaf files and directories for
{N}paths ... - Reading all files.
It is ture?
Please answer to me thx..!
CodePudding user response:
Spark is processing data lazy, but is getting schemas non-lazy.
The spark.sql is reading metadata (e.g. from Hive) and does not know yet how large the input data set will be. I guess that's whats shown there with the small amount.
The spark.read.parquet has to access the actual parquet file and infer the schema (in your red section), therefore the optimizer already knows how large the file will be, thus leading to the larger number and slower processing.
Can you please cache the dataframe and execute an spark action (like df.show or df.count) and the post the df.explain results again. Statistics should be similar after that.