I have a large dataset with a datetime column and I'm trying to engineer a column which contains a count of the number of rows with a timestamp within one second of that row.
I have created a method to do this in R, but it is inefficient and contains the ugly "for i in 1:length(vector)"
s = c()
for (i in 1:length(df$timestamp)){
s[i] = sum(df$timestamp >= df$timestamp[i]-1 & df$timestamp <= df$timestamp[i] 1)
}
I feel like there should be a way to do this without looping and in SQL server - but I'm at a loss. Something like
SELECT *, count(timestamp between timestamp - 1 and timestamp 1) as sec_count
So that querying:
| timestamp |
|---|
| 1/1/2011 11:11:01.2 |
| 1/1/2011 11:11:01.3 |
| 1/1/2011 11:11:01.4 |
| 1/1/2011 11:11:01.5 |
| 1/1/2011 11:11:03 |
| 1/1/2011 11:11:04 |
| 1/1/2011 11:11:15 |
| 1/1/2011 11:11:30 |
Would result in:
| timestamp | sec_count |
|---|---|
| 1/1/2011 11:11:01.2 | 4 |
| 1/1/2011 11:11:01.3 | 4 |
| 1/1/2011 11:11:01.4 | 4 |
| 1/1/2011 11:11:01.5 | 4 |
| 1/1/2011 11:11:03 | 2 |
| 1/1/2011 11:11:04 | 2 |
| 1/1/2011 11:11:15 | 1 |
| 1/1/2011 11:11:30 | 1 |
or similar
CodePudding user response:
Seems like a self-join would do the trick
Select A.timestamp
,Sec_Count = count(*)
From YourTable A
Join YourTable B on B.timestamp between dateadd(SECOND,-1,A.timestamp) and dateadd(SECOND, 1,A.timestamp)
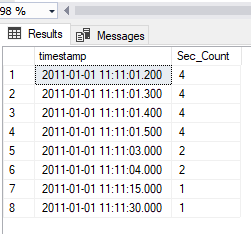
Group By A.timestamp
Results
Update For Duplicate TimeStamps
with cte as (
Select distinct TimeStamp from YourTable
)
Select A.timestamp
,Sec_Count = count(*)
From cte A
Join cte B on B.timestamp between dateadd(SECOND,-1,A.timestamp) and dateadd(SECOND, 1,A.timestamp)
Group By A.timestamp
CodePudding user response:
For each timestamp you can determine 1 second before and 1 second after. When you have that, you can use a correlated subquery to get the result:
DECLARE @Data TABLE (ID INT IDENTITY(1,1) NOT NULL, TS DATETIME NOT NULL);
INSERT INTO @Data(TS) VALUES ('1/1/2011 11:11:01.2'),
('1/1/2011 11:11:01.3'),
('1/1/2011 11:11:01.4'),
('1/1/2011 11:11:01.5'),
('1/1/2011 11:11:03'),
('1/1/2011 11:11:04'),
('1/1/2011 11:11:15'),
('1/1/2011 11:11:30');
;WITH data_with_max_and_min AS (
SELECT ID, TS, DATEADD(second, -1, TS) AS min_ts , DATEADD(second, 1, TS) AS max_ts
FROM @Data
)
SELECT ID, TS, (SELECT COUNT(*) FROM data_with_max_and_min AS d2 WHERE d2.TS BETWEEN d1.min_ts AND d1.max_ts) AS sec_count
FROM data_with_max_and_min AS d1
That gives the results you show in your question.
Another way to get the same results is to join the intermediate table to itself and group. That approach looks like:
DECLARE @Data TABLE (ID INT IDENTITY(1,1) NOT NULL, TS DATETIME NOT NULL);
INSERT INTO @Data(TS) VALUES ('1/1/2011 11:11:01.2'),
('1/1/2011 11:11:01.3'),
('1/1/2011 11:11:01.4'),
('1/1/2011 11:11:01.5'),
('1/1/2011 11:11:03'),
('1/1/2011 11:11:04'),
('1/1/2011 11:11:15'),
('1/1/2011 11:11:30');
;WITH data_with_max_and_min AS (
SELECT ID, TS, DATEADD(second, -1, TS) AS min_ts , DATEADD(second, 1, TS) AS max_ts
FROM @Data
)
SELECT d2.TS, COUNT(*) as sec_count
FROM data_with_max_and_min AS d1
INNER JOIN data_with_max_and_min AS d2 ON d2.min_ts <= d1.TS and d2.max_ts >= d1.TS
GROUP BY d2.TS
CodePudding user response:
An efficient option (if it does not trigger an arithmetic overflow) is to use the dateadd and datediff functions.
count(*) over(partition by ((DATEADD(minute, (DATEDIFF(minute, '', timestamp)), '')))) within_min
Resulting in a minutes version of the output I want that runs quickly.
However, when I attempt to do this at the second scale for my data, it does unfortunately lead to the dateadd arithmetic overflow problem.