I want to classify text with multiple labels. I use TextVectorization layer and CategoricalCrossEntropy function. Here is my model code:
Text Vectorizer:
def custom_standardization(input_data):
print(input_data[:5])
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
Model generation:
MAX_TOKENS_NUM = 5000 # Maximum vocab size.
MAX_SEQUENCE_LEN = 40 # Sequence length to pad the outputs to.
EMBEDDING_DIMS = 100
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(1,), dtype=tf.string))
model.add(vectorize_layer)
model.add(tf.keras.layers.Embedding(MAX_TOKENS_NUM 1, EMBEDDING_DIMS))
model.summary()
model.compile(loss=losses.CategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.CategoricalAccuracy())
FIT :
epochs = 10
history = model.fit(
x_train,
y=y_train,
epochs=epochs)
x_train is a list of texts like ['This is a text about science.', 'This is a text about art',...]
y_train also is a list of texts like ['Science','Art',...]
When I try to run fitting code it gives the following error:
ValueError: Shapes (None,) and (None, 250, 100) are incompatible
What am i doing wrong? And also I'd like to learn if it's a good approach/model for classifying test with multiple labels?
EDIT:
I edited my code according to Frightera's answer. Here is my model:
MAX_TOKENS_NUM = 5000 # Maximum vocab size.
MAX_SEQUENCE_LEN = 40 # Sequence length to pad the outputs to.
EMBEDDING_DIMS = 100
model = tf.keras.models.Sequential()
model.add(tf.keras.Input(shape=(1,), dtype=tf.string))
model.add(vectorize_layer)
model.add(tf.keras.layers.Embedding(MAX_TOKENS_NUM 1, EMBEDDING_DIMS))
model.add(layers.Dropout(0.2))
model.add(layers.GlobalAveragePooling1D())
model.add(layers.Dropout(0.2))
model.add(layers.Dense(len(labels)))
model.summary()
model.compile(loss=losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.SparseCategoricalAccuracy())
And I pass y_train_int instead of y_train by converting categories to indexes with y_train_int = [get_label_index(label) for label in y_train]
epochs = 10
history = model.fit(
x_train,
y=y_train_int,
epochs=epochs)
Now the model fits, but when I check loss function with plt.plot(history.history['loss']) it's an all zero line like below:
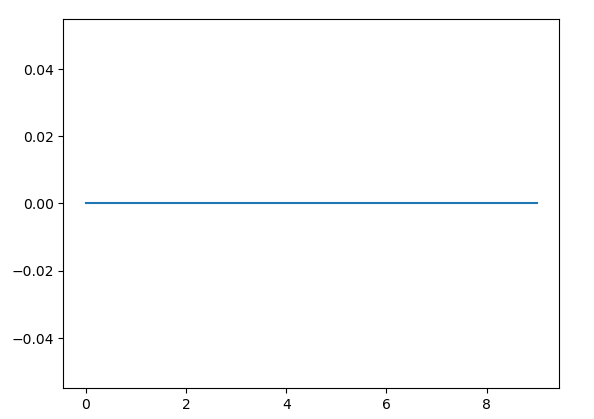
Is this model good for classification. Do I need those layers between input layer and final Dense Layer(Embedding etc.)? What am I doing wrong?
EDIT 2: I have the above model now. I am using SparseCategoricalEntropy and passing to the last Dense layer length of labels which is 78 and now it fits the model.
Now when I use model.predict(x_test), it gives following results:
array([[ 1.3232083 , 3.4263668 , 0.3206688 , ..., -1.9279423 ,
-0.83103067, -5.3442082 ],
[ 0.11507592, -2.0753977 , -0.07149621, ..., -0.27729607,
-1.132122 , -2.4074485 ],
[ 0.87828857, -0.5063573 , 1.5770453 , ..., 0.72519284,
0.50958884, 3.7006462 ],
...,
[ 0.35316354, -3.1919005 , -0.25520897, ..., -1.648859 ,
-2.2707412 , -4.321298 ],
[ 0.89357865, 1.3001428 , 0.17324057, ..., -0.8185719 ,
-1.4108973 , -3.674326 ],
[ 1.6258209 , -0.59622926, 0.7382731 , ..., -0.8473997 ,
-0.90670204, -4.043623 ]], dtype=float32)
How can I convert these to labels?
CodePudding user response:
I resolved this according to the comments as follows for text classification:
- Use Dense layer with number of unique labels in the end of the model.
- Convert string category labels to indexes and use SparseCategoricalCrossEntropy and SparseCategoricalAccuracy in the model.
- When converting results to string labels, get the max valued output and get index of it in the labels list.