I am working with pyspark for the first time and I want to get unique URLs count for consecutively two days. Suppose, one URLs comes in the system today and if that also comes tomorrow, I do NOT want to count that in tomorrow's unique counts. Columns are Date and Url_path
input
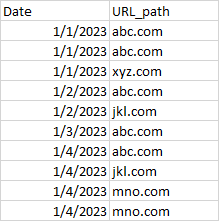
expected output
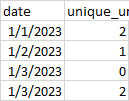 I tried this
I tried this
display(
df.groupBy( F.window(df['date'], "2 day"))
.agg(F.countDistinct(F.col('host_path')).alias("unique_urls"),
F.count(F.col('host_path')).alias("total_urls"))
)
but it's giving me unique counts for that window. I want to get Net New counts for every single day.
CodePudding user response:
I can think this as dropping duplicates with condition then count. The condition is that when the same host_path appears within yesterday or today.
w = Window.partitionBy('host_path').orderBy('date')
# If the last time of the same host_path is more than 1 day, uniq_flag is True (it is unique)
df = (df.withColumn('uniq_flag', F.datediff(F.col('date'), F.lag('date').over(w)) > 1)
# I will only need to count when it is unique or first time
# (uniq_flag = None when first time)
.filter(F.col('uniq_flag').isNull() | (F.col('uniq_flag') == True))
.groupby('date')
.agg(F.count('host_path').alias('unique_urls')))
CodePudding user response:
You can achieve your desired result like this,
- Prepping the dataframe
data = [('1/1/2023', 'abc.com'), ('1/1/2023', 'abc.com'), ('1/1/2023', 'xyz.com'), ('1/2/2023', 'abc.com'), ('1/2/2023', 'jkl.com'), ('1/3/2023', 'abc.com'), ('1/4/2023', 'abc.com'), ('1/4/2023', 'jkl.com'), ('1/4/2023', 'mno.com'), ('1/4/2023', 'mno.com')]
schema = ['date', 'host_path']
df = spark.createDataFrame(data, schema)
df.show()
Output:
-------- ---------
| date|host_path|
-------- ---------
|1/1/2023| abc.com|
|1/1/2023| abc.com|
|1/1/2023| xyz.com|
|1/2/2023| abc.com|
|1/2/2023| jkl.com|
|1/3/2023| abc.com|
|1/4/2023| abc.com|
|1/4/2023| jkl.com|
|1/4/2023| mno.com|
|1/4/2023| mno.com|
-------- ---------
- Use collect_set() to collect all the urls for that day without any duplicates.
from pyspark.sql import Window
w = Window.partitionBy('date').orderBy('date')
df = df.withColumn("all_urls", F.collect_set("host_path").over(w))
df = df.dropDuplicates(['date', 'all_urls'])
df.show(truncate=False)
Output:
-------- --------- ---------------------------
|date |host_path|all_urls |
-------- --------- ---------------------------
|1/1/2023|abc.com |[xyz.com, abc.com] |
|1/2/2023|abc.com |[jkl.com, abc.com] |
|1/3/2023|abc.com |[abc.com] |
|1/4/2023|abc.com |[jkl.com, mno.com, abc.com]|
-------- --------- ---------------------------
- Use lag() to get the URLs that came one day prior
w1 = Window.orderBy('date')
df = df.withColumn("lag_urls", F.lag("all_urls", 1).over(w1))
df.show(truncate=False)
Output:
-------- --------- --------------------------- ------------------
|date |host_path|all_urls |lag_urls |
-------- --------- --------------------------- ------------------
|1/1/2023|abc.com |[xyz.com, abc.com] |null |
|1/2/2023|abc.com |[jkl.com, abc.com] |[xyz.com, abc.com]|
|1/3/2023|abc.com |[abc.com] |[jkl.com, abc.com]|
|1/4/2023|abc.com |[jkl.com, mno.com, abc.com]|[abc.com] |
-------- --------- --------------------------- ------------------
- Get the difference between
all_urlsandlag_urlsusing array_except
df = df.withColumn('difference', F.array_except('all_urls', 'lag_urls'))
df.show(truncate=False)
Output:
-------- --------- --------------------------- ------------------ ------------------
|date |host_path|all_urls |lag_urls |difference |
-------- --------- --------------------------- ------------------ ------------------
|1/1/2023|abc.com |[xyz.com, abc.com] |null |null |
|1/2/2023|abc.com |[jkl.com, abc.com] |[xyz.com, abc.com]|[jkl.com] |
|1/3/2023|abc.com |[abc.com] |[jkl.com, abc.com]|[] |
|1/4/2023|abc.com |[jkl.com, mno.com, abc.com]|[abc.com] |[jkl.com, mno.com]|
-------- --------- --------------------------- ------------------ ------------------
- Get the size/length of the arrays in the
differencecolumn and if null then get the size/length fromall_urls
df.withColumn("unique_urls", F.when(F.size(F.col("difference")) < 0, F.size(F.col("all_urls"))).otherwise(F.size(F.col("difference")))).select("date", "unique_urls").show(truncate=False)
Output:
-------- -----------
|date |unique_urls|
-------- -----------
|1/1/2023|2 |
|1/2/2023|1 |
|1/3/2023|0 |
|1/4/2023|2 |
-------- -----------
- So, everything together looks like this,
from pyspark.sql import Window
w = Window.partitionBy('date').orderBy('date')
w1 = Window.orderBy('date')
df = df.withColumn("all_urls", F.collect_set("host_path").over(w)) \
.dropDuplicates(['date', 'all_urls']) \
.withColumn("lag_urls", F.lag("all_urls", 1).over(w1)) \
.withColumn('difference', F.array_except('all_urls', 'lag_urls')) \
.withColumn("unique_urls", F.when(F.size(F.col("difference")) < 0, F.size(F.col("all_urls"))).otherwise(F.size(F.col("difference")))) \
.select("date", "unique_urls")
df.show(truncate=False)
Output:
-------- -----------
|date |unique_urls|
-------- -----------
|1/1/2023|2 |
|1/2/2023|1 |
|1/3/2023|0 |
|1/4/2023|2 |
-------- -----------