R beginner here in need of some help. I have this dataframe:
dat<-data.frame(Name=c("A","A","A","A","A","B","B","B","B","B","C","C","C","C","C"),
Score=c(1,2,3,4,5,1,2,3,4,5,1,2,3,4,5),
Frequency=c(9,11,10,5,5,3,7,10,5,5,20,3,3,2,2))
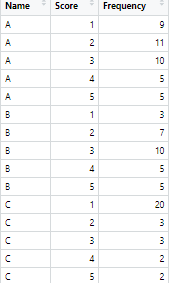
And I want to sum the frequencies of rows with scores 2-3 and 4-5 by name, and rename the scores High (score 1), Medium (scores 2-3) or Low (scores 4-5). Basically my dataframe should look like this:
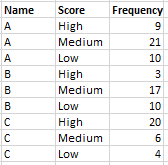
Is there a more straightforward way to do this? Thanks a lot!
CodePudding user response:
You could first use case_when to convert the score to right class en then group_by and sumamrise your data like this:
library(dplyr)
dat %>%
mutate(Score = case_when(Score == 1 ~ "High",
Score %in% c(2,3) ~ "Medium",
TRUE ~ "Low")) %>%
group_by(Name, Score) %>%
summarise(Frequency = sum(Frequency))
#> `summarise()` has grouped output by 'Name'. You can override using the
#> `.groups` argument.
#> # A tibble: 9 × 3
#> # Groups: Name [3]
#> Name Score Frequency
#> <chr> <chr> <dbl>
#> 1 A High 9
#> 2 A Low 10
#> 3 A Medium 21
#> 4 B High 3
#> 5 B Low 10
#> 6 B Medium 17
#> 7 C High 20
#> 8 C Low 4
#> 9 C Medium 6
Created on 2023-01-11 with reprex v2.0.2
CodePudding user response:
Here is a base R approach.
First, create Category based on the Score using cut:
dat$Category <- cut(dat$Score,
breaks = c(1, 2, 4, 5),
labels = c("High", "Medium", "Low"),
include.lowest = T,
right = F)
Then you can aggregate based on both Name and Category to get the final result:
aggregate(Frequency ~ Name Category, data = dat, sum)
Output
Name Category Frequency
1 A High 9
2 B High 3
3 C High 20
4 A Medium 21
5 B Medium 17
6 C Medium 6
7 A Low 10
8 B Low 10
9 C Low 4