I've a table which has emp_id, emp_desg, and mgr_id. I'm trying to find and print the employees who are reporting to lower-level hierarchy or same level hierarchy or superior-level hierarchy. I have a mapping for the hierarchy levels and a mapping to find opposing role reporting, if the cases in 2nd MAPPING matches in the table, then it should print it.
1st MAPPING (Hierarchy Levels)

2nd MAPPING (Opposing role) - These records need to be printed.

I need to iterate through each employee and their managers. If the levels of emp and mgr matches with the 2nd mapping, I need to print it. Please help me to solve this, thanks in advance.
| emp_id | emp_desg | mgr_id |
|---|---|---|
| 111 | ASM | 112 |
| 112 | ASM | 116 |
| 113 | BSM | 114 |
| 114 | CSM | 115 |
| 115 | ASM | 116 |
| 116 | DSM | 117 |
Expected output:
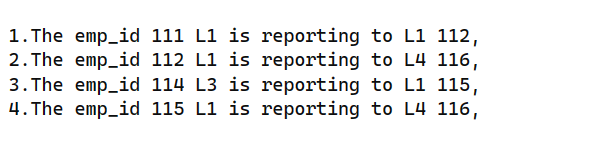
df['emp_role'] = df['emp_desg'].map(hrchy_levels)
df['mgr_role'] = df['mgr_desg'].map(hrchy_levels)
Is there a way to compare 'emp_role' and 'mgr_role' with ranks_subords and just print the emp_id and mgr_id. I need not want to change anything in df, So after printing, I'll remove the added new columns emp_role and mgr_role. Thanks!
CodePudding user response:
We start with defining the needed mappings for hierarchy and subordination.
hrchy_levels = {'ASM':'L1', 'BSM':'L2', 'CSM':'L3', 'DSM':'L4'}
ranks_subords = [('L1' , 'L1'),('L1' , 'L4'),('L2' , 'L1'),('L2' , 'L2'),('L3' , 'L3'),('L3' , 'L1'),('L3' , 'L2'),('L4' , 'L1'),('L4' , 'L2'),('L4' , 'L3')]
Then map manager ids to employee ids:
df['mgr_desg'] = df['mgr_id'].map(dict(df[['emp_id', 'emp_desg']].values))
Making replacements for level descriptions into another df and filtering by rank relations:
df2 = df.replace({'emp_desg': hrchy_levels, 'mgr_desg': hrchy_levels})
df2[df2.apply(lambda x: (x['emp_desg'], x['mgr_desg']) in ranks_subords, axis=1)]
emp_id emp_desg mgr_id mgr_desg
0 111 L1 112 L1
1 112 L1 116 L4
3 114 L3 115 L1
4 115 L1 116 L4
Now, it's easy to iterate over the rows and print a formatted output.