I have a dataset about patients having diabetes or not with many instances.
Each instance is classified (labelled) with a particular class (binary, 0 or 1)
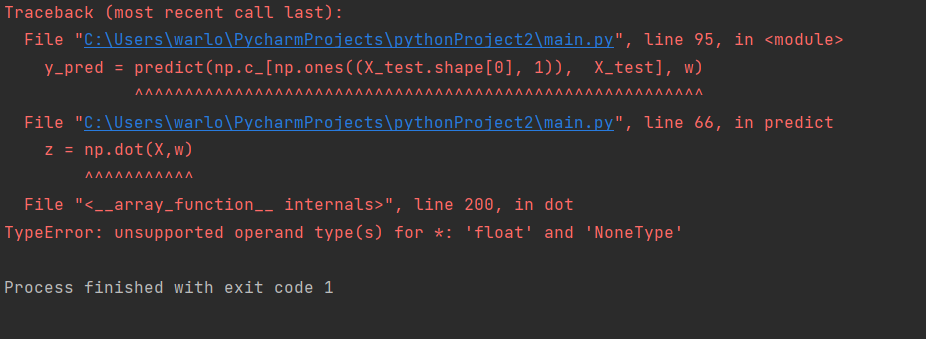
I have problems when trying to predict Y^
but I have problems :
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
def load_cvs(filename):
data = []
labels = []
with open(filename, 'r') as f:
for line in f:
items = line.split(",")
data.append([float(items[0]),float(items[1]),float(items[2]),float(items[3]),float(items[4]),float(items[5])])
labels.append(int(items[6]))
return np.array(data), np.array(labels)
X,y = load_cvs('diabetes.csv')
df = pd.read_csv("diabetes.csv")
#Glucose;BloodPressure;SkinThickness;Insulin;BMI;Age
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2, random_state=33)
def sigmoid(z):
return 1 / (1 np.exp(-z))
def predict(X,w):
z = np.dot(X,w)
return sigmoid(z)
def cost(y , y_pred):
return -np.mean(y * np.log(y_pred) (1 - y) * np.log(1 - y_pred))
def train(X, y, epochs = 1000, lr =0.02):
X = np.c_[np.ones((X.shape[0], 1)), X]
w = np.random.randn(X.shape[1])
for epoch in range(epochs):
y_pred = predict(X,w)
error = y_pred - y
gradient = np.dot(X.T, error) / y.size
w -= lr * gradient
if epoch % 100 == 0:
c = cost(y,y_pred)
print(f'Epoch{epoch}: cost = {c}')
return w
w = train(X_train,y_train,epochs=1000, lr=0.02)
X_test=X_test
y_pred = predict(np.c_[np.ones((X_test.shape[0], 1)), X_test], w)
I get this error message:
TypeError: unsupported operand type(s) for *: 'float' and 'NoneType'
CodePudding user response:
It seems you have null values in your data, you have to drop or fill them:
X, y = load_cvs('diabetes.csv')
df = pd.read_csv('diabetes.csv')
df = df.dropna() # <- HERE
To find rows with null values, use:
X, y = load_cvs('diabetes.csv')
df = pd.read_csv('diabetes.csv')
nandf = df[df.isna().any(axis=1)] # <- HERE
CodePudding user response:
df.dropna(inplace=True)
I think you should try this.