I have a DataFrame that looks like this:
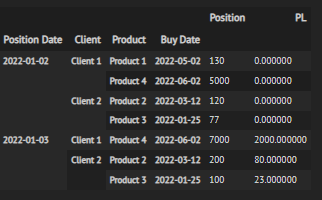
The code to build it is:
df = pd.DataFrame()
df['Client'] = ['Client 1', 'Client 1','Client 2','Client 2', 'Client 1', 'Client 2','Client 2']
df['Product'] = ['Product 1', 'Product 4', 'Product 2', 'Product 3', 'Product 4', 'Product 2', 'Product 3']
df['Position Date'] = ['2022-01-02', '2022-01-02', '2022-01-02', '2022-01-02', '2022-01-03', '2022-01-03', '2022-01-03']
df['Buy Date'] = ['2022-05-02', '2022-06-02', '2022-03-12', '2022-01-25', '2022-06-02', '2022-03-12', '2022-01-25']
df['Position'] = [130, 5000, 120, 77, 7000, 200, 100]
df['PL'] = [0,0,0,0, 50, 2000, 80, 100]
df = df.set_index(['Position Date','Client', 'Product', 'Buy Date'], drop=True)
df['PL'] = df.groupby(level=['Client', 'Product', 'Buy Date']).diff().fillna(0)
So, now I need to create a new column X that divides a the "current day" PL (index 0) by the last day Position (with index -1).
For example: on the day 2022-01-03, Client 2, product 2 the x would be:
X = PL[index 0] / Position[-1] = 80 / 120
The expected output would be:
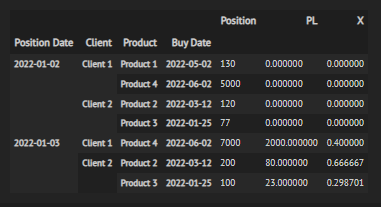
As the first day's values are 0 and the others are: 2000/5000, 80/120, 23/77
I have asked a similar question before, and @mozway kindly solved it for me using a reindex solution:
df['output'] = df['PL'].div(df.loc[df.index[0][0], 'Position']
.reindex(df.droplevel('Position Date').index).values
)
But I forgot a crucial point in this test database, for some Position Dates we don't have the same information about the positions. For example, the group 2022-01-03 / Client 1 doesn't have the same shape as the group 2022-01-02 / Client 1. The question would be how to apply the division regardless the shape of each group.
CodePudding user response:
IIUC, you can use groupby then apply your function:
>>> (df.groupby(level=['Client', 'Product', 'Buy Date'], as_index=False)
.apply(lambda x: x['PL'] / x['Position'].shift())
.fillna(0).to_frame('X').droplevel(0)).sort_index()
X
Position Date Client Product Buy Date
2022-01-02 Client 1 Product 1 2022-05-02 0.000000
Product 4 2022-06-02 0.000000
Client 2 Product 2 2022-03-12 0.000000
Product 3 2022-01-25 0.000000
2022-01-03 Client 1 Product 4 2022-06-02 0.400000
Client 2 Product 2 2022-03-12 0.666667
Product 3 2022-01-25 0.298701