I've been trying to convert a json response from an api to a full panadas dataframe. I tried json normalize to achieve it unfortunately i was able to split it only to one level.
response = {
"data":
{
"result": [
{
"agent_info": {
"agent_id": "q321",
"instances": [
{
"last_run_end": "2023-01-19T15:15:55.491Z",
"mode": "Advanced",
"is_enabled": "True",
"run_duration": "00:00:00:031",
"name": "john",
"status": "Running",
"node_id": "wq"
},
{
"last_run_end": "2023-01-19T15:15:55.491Z",
"mode": "Advanced",
"is_enabled": "True",
"run_duration": "00:00:00:031",
"name": "chris",
"status": "Running",
"node_id": "wq"
}
]
}
},
{
"agent_info": {
"agent_id": "q123",
"instances": [
{
"last_run_end": "2023-01-19T15:15:55.491Z",
"mode": "Advanced",
"is_enabled": "True",
"run_duration": "00:00:00:031",
"name": "john",
"status": "Running",
"node_id": "wq"
}
]
}
}
]
},
"status": 200,
"servedBy": "ABC"
}
df=pd.json_normalize(response,["data",["result",]],["status","servedBy"])
df
Result
agent_info.agent_id agent_info.instances \
0 q321 [{'last_run_end': '2023-01-19T15:15:55.491Z', ...
1 q123 [{'last_run_end': '2023-01-19T15:15:55.491Z', ...
status servedBy
0 200 ABC
1 200 ABC
what i would like is that every key value to be a seperate column.. Any help or pointers ?
CodePudding user response:
You can first explode 'agent_info.instances' then create a dataframe from the exploded values that you will concat to the other columns:
df = pd.json_normalize(response,["data",["result",]],["status","servedBy"]).explode('agent_info.instances').reset_index(drop=True)
nested_val = pd.DataFrame(df['agent_info.instances'].values.tolist())
print(pd.concat([df.drop('agent_info.instances', axis=1), nested_val], axis=1))
output:
agent_info.agent_id status servedBy last_run_end mode is_enabled run_duration name status node_id
0 q321 200 ABC 2023-01-19T15:15:55.491Z Advanced True 00:00:00:031 john Running wq
1 q321 200 ABC 2023-01-19T15:15:55.491Z Advanced True 00:00:00:031 chris Running wq
2 q123 200 ABC 2023-01-19T15:15:55.491Z Advanced True 00:00:00:031 john Running wq
CodePudding user response:
Does this work for you?
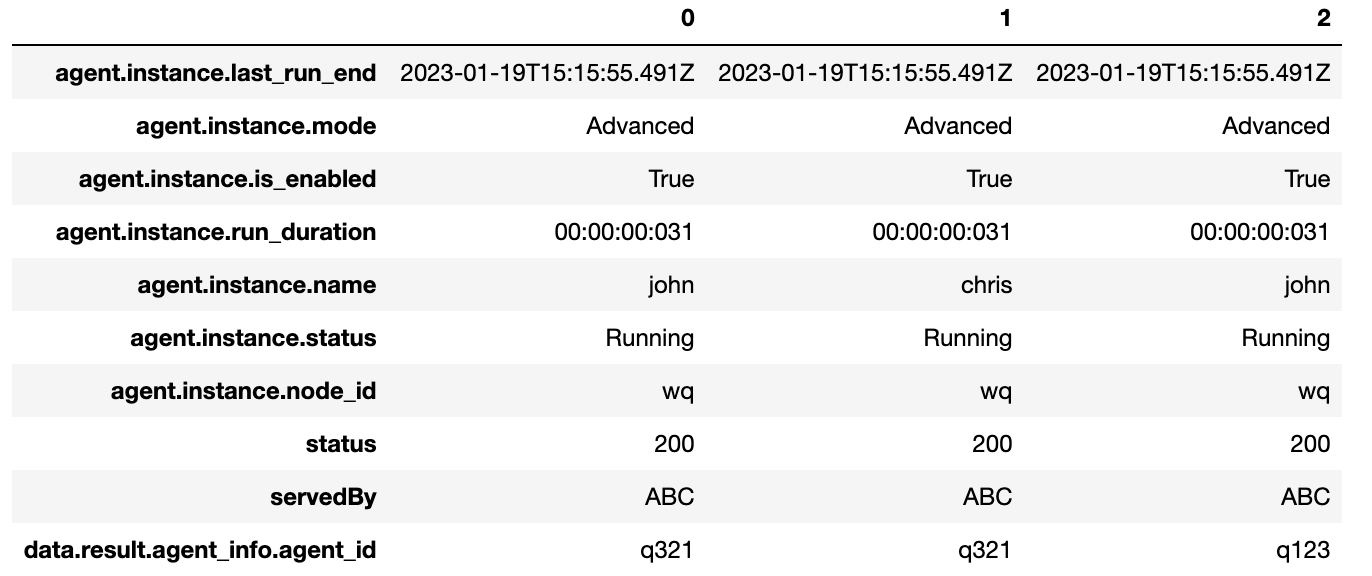
df=pd.json_normalize(
data = response,
record_path = ["data","result","agent_info","instances"],
meta = ["status","servedBy",["data","result","agent_info","agent_id"]],
record_prefix = "agent.instance.",
)
print(df.T)
Output (transposed to fit better on the screen)