I am trying to extract the first names of the titles of the columns such as pack_10, pack_18 and pack_20 and group all of them with sum. Below you can see my data
df<-data.frame(
packs_10_value5=c(100,0,0,0,0),
packs_18_value9=c(200,0,0,0,0),
packs_20_value13=c(300,0,0,0,0),
packs_10_value15=c(100,0,0,0,0),
packs_18_value17=c(200,0,0,0,0),
packs_20_value18=c(300,0,0,0,0)
)
df
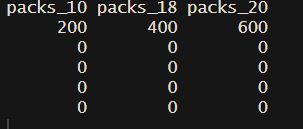
So can anybody help me with how to solve this?
CodePudding user response:
You can split the columns and apply rowSums by group:
library(purrr)
split.default(df, f = gsub("_value.*", "", names(df))) %>%
map_dfc(rowSums)
# A tibble: 5 × 3
packs_10 packs_18 packs_20
<dbl> <dbl> <dbl>
1 200 400 600
2 0 0 0
3 0 0 0
4 0 0 0
5 0 0 0
CodePudding user response:
A bit more convoluted/less elegant, but you could also create a row_number column, pivot_longer by all other columns, do the regex, aggregate by the clean column name and each row and pivot_wider back:
library(dplyr)
library(tidyr)
df %>%
mutate(rn = row_number()) %>%
pivot_longer(cols = -rn) %>%
group_by(name = sub('_value\\d ', '', name), rn) %>%
summarise(value = sum(value, na.rm = TRUE)) %>%
pivot_wider(names_from = 'name', values_from = 'value') %>%
select(-rn)
Output:
# A tibble: 5 x 3
packs_10 packs_18 packs_20
<dbl> <dbl> <dbl>
1 200 400 600
2 0 0 0
3 0 0 0
4 0 0 0
5 0 0 0