I have a dataset with data about political careers. Every politician has a unique identifier nuber (ui) and can occur in multiple electoral terms (electoral_terms). Every electoral term equals a period of 4 years in which the politician is in office.
Now I would like to find out, which academic titles (academic_title) occure in the dataset and how often they occur.
The problem is that every politican is potentially mentioned multiple times and I'm only interested in the last state of their academic title.
E.g. 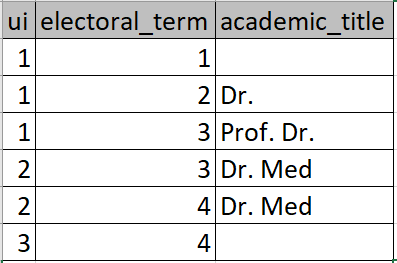 the correct answer would be:
1x Prof. Dr.
1x Dr. Med
the correct answer would be:
1x Prof. Dr.
1x Dr. Med
Thanks in advance!
I tried this Command:
Stammdaten_academic<- Stammdaten |> arrange(ui, academic_title) |> distinct(ui, .keep_all = TRUE)``
Stammdaten_academic is the dataframe where every politician is only mentioned once (similar as a Group-By command would do). Stammdaten is the original dataframe with multiple occurences of each politician.
Result: I got the academic title that was mentioned in the first occuring row of each politician.
Problem: I would like to receive the last state of everyones' academic title!
CodePudding user response:
library(dplyr)
Stammdaten_academic <- Stammdaten |>
group_by(ui) |>
arrange(electoral_term) |>
slice(n)
Should give you the n'th row from each group (ui) where n is the number of items in that group.
CodePudding user response:
Academic titles are progressive and a person does not stop being a doctor or such.
I believe this solves your problem
# create your data frame
df <- data.frame(ui = c(1,1,1,2,2,3),
electoral_term = c(1,2,3,3,4,4),
academit_title = c(NA, "Dr.","Prof. Dr.","Dr. Med.","Dr. Med.", NA))
# get latest titles
titles <- df |>
dplyr::group_by(ui) |>
dplyr::summarise_at(vars(electoral_term), max) |>
dplyr::left_join(df, by = c("ui", "electoral_term")) |>
tidyr::drop_na() # in case you don't want the people without title
#counts occurences
table(titles$academic_title)