I'm have a dataset like the one below and I'm looking to add the last column to this data.
The logic behind a session, is that it groups all rows by user_id into one session if they are within 5 days of the first event in a session.
In the example below, the users first event is 2023-01-01 which kicks off the first session. That is, although there is less than 5 days between 2023-01-04 and 2023-01-06, this is a new session as the 5 day counter resets when it's reached.
user_id timestamp session
user_1 2023-01-01 session_1
user_1 2023-01-01 session_1
user_1 2023-01-04 session_1
user_1 2023-01-06 session_2
user_1 2023-01-16 session_3
user_1 2023-01-16 session_3
user_1 2023-01-17 session_3
My data contains several users. How do I efficently add this session column in BigQuery?
CodePudding user response:
It seems to be kind of cumulative capped sum problem. If I understood your requirements correctly, you might consider below.
I've answered similar problem 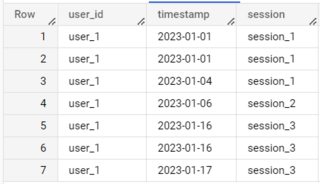
CodePudding user response:
Try the following:
with mydata as
(
select 'user_1' as user_id ,cast('2023-01-01' as date) as timestamp_
union all
select 'user_1' ,cast('2023-01-01' as date)
union all
select 'user_1' ,cast('2023-01-04' as date)
union all
select 'user_1' ,cast('2023-01-06' as date)
union all
select 'user_1' ,cast('2023-01-16' as date)
union all
select 'user_1' ,cast('2023-01-16' as date)
union all
select 'user_1' ,cast('2023-01-17' as date)
)
select user_id, timestamp_,
'session_' || dense_rank() over (partition by user_id order by div(df, 5)) as session
from
(
select *,
date_diff(timestamp_, min(timestamp_) over (partition by user_id), day) df
from mydata
) T
order by user_id, timestamp_
Output according to your input data:
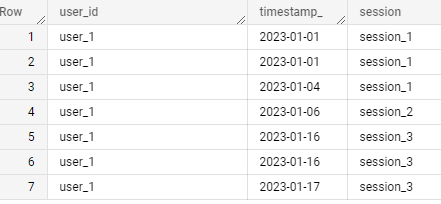
The logic here is to find the date difference between each date and the the minimum date for each user, then perform an integer division by 5 on that data diff to create groups for the dates.
The use of dense_rank is to remove gaps that may occur from the grouping, if it's not important to have sessions ordered with no gaps you could remove it and use div(df, 5) instead.