I am currently trying to calculate the rolling average of one column in my pandas dataframe over many rolling periods. My dataframe has one column of interest where I wish to calculate a rolling average from 2-40 periods and have the same dataframe and indexes know these values. This has proven a bit to slow as my dataframe has ~6,000,000 rows these windows are calculated over.
I've provided some sample data at the bottom that can be copy/pasted into the pd.DataFrame method. That is what my variable "df" stores
Current solution
df = pd.DataFrame(*dictionary at thebottom*)
for i in range(2, 41):
df[f'roll_{i}'] = df['col1'].rolling(i).mean()
Other methods:
I've tried giving .mean the engine='pyarrow' parameter, but that doesn't seem to do much. Can someone help point me to speeding this calculation up?
The Data
{Timestamp('2022-10-18 16:10:00'): 18.1065,
Timestamp('2022-10-18 16:11:00'): 18.120449999999998,
Timestamp('2022-10-18 16:12:00'): 18.1293,
Timestamp('2022-10-18 16:13:00'): 18.13035,
Timestamp('2022-10-18 16:14:00'): 18.1245,
Timestamp('2022-10-18 16:15:00'): 18.1049,
Timestamp('2022-10-18 16:16:00'): 18.1014,
Timestamp('2022-10-18 16:17:00'): 18.103499999999997,
Timestamp('2022-10-18 16:18:00'): 18.09375,
Timestamp('2022-10-18 16:19:00'): 18.0906,
Timestamp('2022-10-18 16:20:00'): 18.092699999999997,
Timestamp('2022-10-18 16:21:00'): 18.0855,
Timestamp('2022-10-18 16:22:00'): 18.055349999999997,
Timestamp('2022-10-18 16:23:00'): 18.05745,
Timestamp('2022-10-18 16:24:00'): 18.06645,
Timestamp('2022-10-18 16:25:00'): 18.06945,
Timestamp('2022-10-18 16:26:00'): 18.06465,
Timestamp('2022-10-18 16:27:00'): 18.062549999999998,
Timestamp('2022-10-18 16:28:00'): 18.06645,
Timestamp('2022-10-18 16:29:00'): 18.060449999999996,
Timestamp('2022-10-18 16:30:00'): 18.042675,
Timestamp('2022-10-18 16:31:00'): 18.046349999999997,
Timestamp('2022-10-18 16:32:00'): 18.0456,
Timestamp('2022-10-18 16:33:00'): 18.0444,
Timestamp('2022-10-18 16:34:00'): 18.039150000000003,
Timestamp('2022-10-18 16:35:00'): 18.040200000000002,
Timestamp('2022-10-18 16:36:00'): 18.039675000000003,
Timestamp('2022-10-18 16:37:00'): 18.0423,
Timestamp('2022-10-18 16:38:00'): 18.044249999999998,
Timestamp('2022-10-18 16:39:00'): 18.044249999999998,
Timestamp('2022-10-18 16:40:00'): 18.04035,
Timestamp('2022-10-18 16:41:00'): 18.0414,
Timestamp('2022-10-18 16:42:00'): 18.040499999999998,
Timestamp('2022-10-18 16:43:00'): 18.037349999999996,
Timestamp('2022-10-18 16:44:00'): 18.0213,
Timestamp('2022-10-18 16:45:00'): 18.01455,
Timestamp('2022-10-18 16:46:00'): 18.031200000000002,
Timestamp('2022-10-18 16:47:00'): 18.03225,
Timestamp('2022-10-18 16:48:00'): 18.02055,
Timestamp('2022-10-18 16:49:00'): 18.001875000000002,
Timestamp('2022-10-18 16:50:00'): 18.01735,
Timestamp('2022-10-18 16:51:00'): 18.02295,
Timestamp('2022-10-18 16:52:00'): 18.024,
Timestamp('2022-10-18 16:53:00'): 18.028200000000002,
Timestamp('2022-10-18 16:54:00'): 18.02295,
Timestamp('2022-10-18 16:55:00'): 18.02505,
Timestamp('2022-10-18 16:56:00'): 18.0219,
Timestamp('2022-10-18 16:57:00'): 18.0177,
Timestamp('2022-10-18 16:58:00'): 18.03225,
Timestamp('2022-10-18 16:59:00'): 18.0375}
Timestamp('2022-10-18 16:57:00'): 18.0177,
Timestamp('2022-10-18 16:58:00'): 18.03225,
Timestamp('2022-10-18 16:59:00'): 18.0375}
CodePudding user response:
I got 4-5x speed improvement using bottleneck package
import bottleneck
@profile
def main():
df = pd.DataFrame(pd.Series(data), columns=["col1"])
df = df.loc[df.index.repeat(10000)]
df2 = df.copy(deep=True)
fasterMethod(df2)
standardMethod(df)
def standardMethod(df):
for i in range(2, 41):
df[f'roll_{i}'] = df['col1'].rolling(i).mean()
def fasterMethod(df):
values = df['col1'].values
for i in range(2, 41):
df[f'roll_{i}'] = bottleneck.move_mean(values, i)
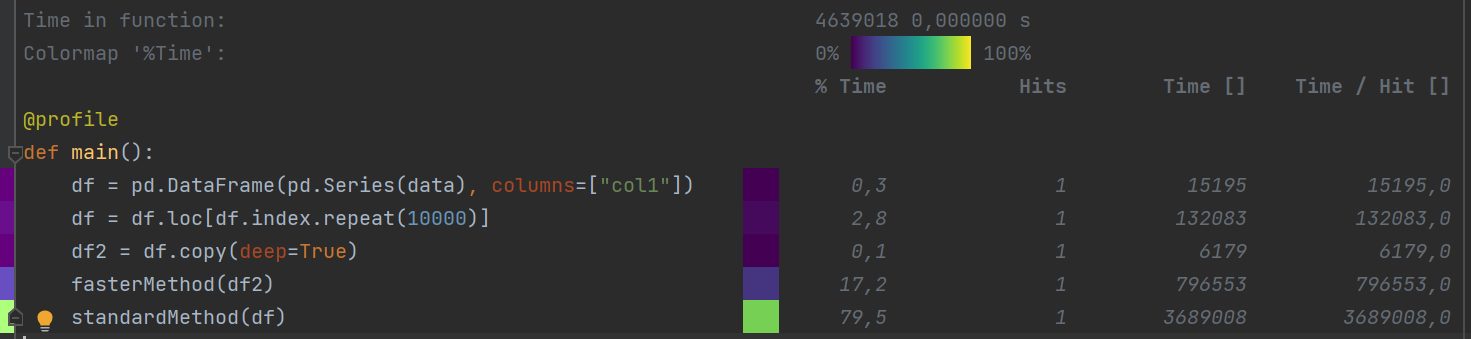
There are differences between results at numerical precision level (10^-14 or so).
In case someone wanted to improve on my answer, here is full code:
import pandas as pd
from line_profiler_pycharm import profile
import bottleneck
data = {
pd.Timestamp('2022-10-18 16:10:00'): 18.1065,
pd.Timestamp('2022-10-18 16:11:00'): 18.120449999999998,
pd.Timestamp('2022-10-18 16:12:00'): 18.1293,
pd.Timestamp('2022-10-18 16:13:00'): 18.13035,
pd.Timestamp('2022-10-18 16:14:00'): 18.1245,
pd.Timestamp('2022-10-18 16:15:00'): 18.1049,
pd.Timestamp('2022-10-18 16:16:00'): 18.1014,
pd.Timestamp('2022-10-18 16:17:00'): 18.103499999999997,
pd.Timestamp('2022-10-18 16:18:00'): 18.09375,
pd.Timestamp('2022-10-18 16:19:00'): 18.0906,
pd.Timestamp('2022-10-18 16:20:00'): 18.092699999999997,
pd.Timestamp('2022-10-18 16:21:00'): 18.0855,
pd.Timestamp('2022-10-18 16:22:00'): 18.055349999999997,
pd.Timestamp('2022-10-18 16:23:00'): 18.05745,
pd.Timestamp('2022-10-18 16:24:00'): 18.06645,
pd.Timestamp('2022-10-18 16:25:00'): 18.06945,
pd.Timestamp('2022-10-18 16:26:00'): 18.06465,
pd.Timestamp('2022-10-18 16:27:00'): 18.062549999999998,
pd.Timestamp('2022-10-18 16:28:00'): 18.06645,
pd.Timestamp('2022-10-18 16:29:00'): 18.060449999999996,
pd.Timestamp('2022-10-18 16:30:00'): 18.042675,
pd.Timestamp('2022-10-18 16:31:00'): 18.046349999999997,
pd.Timestamp('2022-10-18 16:32:00'): 18.0456,
pd.Timestamp('2022-10-18 16:33:00'): 18.0444,
pd.Timestamp('2022-10-18 16:34:00'): 18.039150000000003,
pd.Timestamp('2022-10-18 16:35:00'): 18.040200000000002,
pd.Timestamp('2022-10-18 16:36:00'): 18.039675000000003,
pd.Timestamp('2022-10-18 16:37:00'): 18.0423,
pd.Timestamp('2022-10-18 16:38:00'): 18.044249999999998,
pd.Timestamp('2022-10-18 16:39:00'): 18.044249999999998,
pd.Timestamp('2022-10-18 16:40:00'): 18.04035,
pd.Timestamp('2022-10-18 16:41:00'): 18.0414,
pd.Timestamp('2022-10-18 16:42:00'): 18.040499999999998,
pd.Timestamp('2022-10-18 16:43:00'): 18.037349999999996,
pd.Timestamp('2022-10-18 16:44:00'): 18.0213,
pd.Timestamp('2022-10-18 16:45:00'): 18.01455,
pd.Timestamp('2022-10-18 16:46:00'): 18.031200000000002,
pd.Timestamp('2022-10-18 16:47:00'): 18.03225,
pd.Timestamp('2022-10-18 16:48:00'): 18.02055,
pd.Timestamp('2022-10-18 16:49:00'): 18.001875000000002,
pd.Timestamp('2022-10-18 16:50:00'): 18.01735,
pd.Timestamp('2022-10-18 16:51:00'): 18.02295,
pd.Timestamp('2022-10-18 16:52:00'): 18.024,
pd.Timestamp('2022-10-18 16:53:00'): 18.028200000000002,
pd.Timestamp('2022-10-18 16:54:00'): 18.02295,
pd.Timestamp('2022-10-18 16:55:00'): 18.02505,
pd.Timestamp('2022-10-18 16:56:00'): 18.0219,
pd.Timestamp('2022-10-18 16:57:00'): 18.0177,
pd.Timestamp('2022-10-18 16:58:00'): 18.03225,
pd.Timestamp('2022-10-18 16:59:00'): 18.0375}
@profile
def main():
df = pd.DataFrame(pd.Series(data), columns=["col1"])
df = df.loc[df.index.repeat(10000)]
df2 = df.copy(deep=True)
fasterMethod(df2)
standardMethod(df)
def standardMethod(df):
for i in range(2, 41):
df[f'roll_{i}'] = df['col1'].rolling(i).mean()
def fasterMethod(df):
values = df['col1'].values
for i in range(2, 41):
df[f'roll_{i}'] = bottleneck.move_mean(values, i)
if __name__ == '__main__':
main()