The title might be a bit confusing here, but in essence: We have a dataframe, let’s say like this:
| SKUCODE | PROCCODE | RUNCODE | RSNCODE | BEGTIME | ENDTIME | RSNNAME | |
|---|---|---|---|---|---|---|---|
| 0 | 218032 | A | 21183528 | 1010 | 2020-11-19 04:00 | 2020-11-19 04:15 | Bank holidays |
| 1 | 218032 | A | 21183959 | 300.318 | 2021-01-27 10:50 | 2021-01-27 10:53 | Base paper roll change |
| 2 | 218032 | A | 21183959 | 300.302 | 2021-01-27 11:50 | 2021-01-27 11:53 | Product/grade change |
| 3 | 218032 | A | 21183959 | 300.302 | 2021-01-27 12:02 | 2021-01-27 13:12 | Product/grade change |
| 4 | 200402 | A | 21184021 | 300.302 | 2021-01-27 13:16 | 2021-01-27 13:19 | Product/grade change |
Where each row is a break event happening on a production line. As can be seen, some singular break events (common RSNNAME) are spread out on multiple consecutive rows (for one data gathering reason or another), and we would like to compress all of these into just one row, for example compressing the rows 2 through 4 to a single row in our example dataframe, resulting in something like this:
| SKUCODE | PROCCODE | RUNCODE | RSNCODE | BEGTIME | ENDTIME | RSNNAME | |
|---|---|---|---|---|---|---|---|
| 0 | 218032 | A | 21183528 | 1010 | 2020-11-19 04:00 | 2020-11-19 04:15 | Bank holidays |
| 1 | 218032 | A | 21183959 | 300.318 | 2021-01-27 10:50 | 2021-01-27 10:53 | Base paper roll change |
| 2 | 218032 | A | 21183959 | 300.302 | 2021-01-27 11:50 | 2021-01-27 13:19 | Product/grade change |
The resulting one row would have the BEGTIME (signifying the start of the break) of the first row that was combined, and the ENDTIME (signifying the end of the break) of the last row that was combined, this way making sure we capture the correct timestamps from the entire break event.
If we want to make the problem harder still, we might want to add a time threshold for row combining. Say, if there is a period of more than 15 minutes between (the ENDTIME of the former and the BEGTIME of the latter) two different rows seemingly of the same row event, we would treat them as separate ones instead.
This is accomplished quite easily through iterrows by comparing one row to the next, checking if they contain a duplicate value in the RSNNAME column, and grabbing the ENDTIME of the latter one onto the former one if that is the case. The latter row can then be dropped as useless. Here we might also introduce logic to see if the seemingly singular break events might actually be telling of two different ones of the same nature merely happening some time apart of each other.
However, using iterrows for this purpose gets quite slow. Is there a way to figure out this problem through vectorized functions or other more efficient means? I've played around with shifting the rows around and comparing to each other - shifting and comparing two adjacent rows is quite simple and allows us to easily grab the ENDTIME of the latter row if a duplicate is detected, but we run into issues in the case of n consecutive duplicate causes.
Another idea would be to create a boolean mask to check if the row below the current one is a duplicate, resulting in a scenario where, in the case of multiple consecutive duplicate rows, we have multiple corresponding consecutive "True" labels, the last of which before a "False" label signifies the last row where we would want to grab the ENDTIME from for the first consecutive "True" label of that particular series of consecutive "Trues". I'm yet to find a way to implement this in practice, however, using vectorization.
CodePudding user response:
For the basic problem, drop_duplicates can be used. Essentially, you
- drop the duplicates on the
RSNNAMEcolumn, keeping the first occurrence - replace the
ENDTIMEcolumn with the end times by dropping duplicates again, this time keeping the last occurrence.
(
df.drop_duplicates("RSNNAME", keep="first").assign(
ENDTIME=df.drop_duplicates("RSNNAME", keep="last").ENDTIME.values
)
)
(By using the .values we ignore the index in the assignment.)
To give you an idea for the more complex scenario: You are on the right track with your last idea. You want to .shift the column in question by one row and compare that to the original column. That gives you flags where new consecutive events start:
>>> df.RSNNAME != df.shift().RSNNAME
0 True
1 True
2 True
3 False
4 False
Name: RSNNAME, dtype: bool
To turn that into something .groupby-able, you compute the cumulative sum:
>>> (df.RSNNAME != df.shift().RSNNAME).cumsum()
0 1
1 2
2 3
3 3
4 3
Name: RSNNAME, dtype: int64
For your case, one option could be to extend the df.RSNNAME != df.shift().RSNNAME with some time difference to get the proper flags but I suggest you play a bit with this shift/cumsum approach.
CodePudding user response:
df1 looks like :-
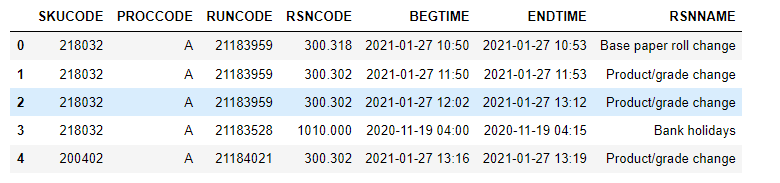
new_df = pd.DataFrame(columns=df1.columns)
for name,df in df1.groupby([(df1.RSNNAME != df1.RSNNAME.shift()).cumsum()] ) :
if df.shape[0] == 1 :
new_df = pd.concat([new_df,df])
else :
df.iloc[0, df.columns.get_loc('ENDTIME')] = df.iloc[-1]["ENDTIME"]
new_df = pd.concat([new_df,df.head(1)])
new_df looks like :-

If you really think that I was using chatgpt then how do you explain all this?
Be greatful that someone is trying to help you.