ID|FLAG|TMST
1|1|2022-01-01
1|1|2022-01-02
...(all dates between 01-02 and 02-05 have 1, there are rows for all these dates)
1|1|2022-02-15
1|0|2022-02-16
1|0|2022-02-17
...(all dates between 02-17 and 05-15 have 0, there are rows for all these dates)
1|0|2022-05-15
1|1|2022-05-16
->
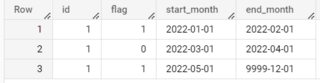
ID|FLAG|STRT_MONTH|END_MONTH
1|1|202201|202202
1|0|202203|202204
1|1|202205|999912
I have the first dataset and I am trying to get the second dataset. How can I write bigquery SQL to group by the ID then get the start and end month of when a flag changes? If a specific month has both 0,1 flag like month 202202, I would like to consider that month to be a 1.
CodePudding user response:
You might consider below gaps and islands approach.
WITH sample_table AS (
SELECT 1 id, 1 flag, DATE '2022-01-01' tmst UNION ALL
SELECT 1 id, 1 flag, '2022-01-02' tmst UNION ALL
-- (all dates between 01-02 and 02-05 have 1, there are rows for all these dates)
SELECT 1 id, 1 flag, '2022-02-15' tmst UNION ALL
SELECT 1 id, 0 flag, '2022-02-16' tmst UNION ALL
SELECT 1 id, 0 flag, '2022-02-17' tmst UNION ALL
SELECT 1 id, 0 flag, '2022-03-01' tmst UNION ALL
SELECT 1 id, 0 flag, '2022-04-01' tmst UNION ALL
-- (all dates between 02-17 and 05-15 have 0, there are rows for all these dates)
SELECT 1 id, 0 flag, '2022-05-15' tmst UNION ALL
SELECT 1 id, 1 flag, '2022-05-16' tmst
),
aggregation AS (
SELECT id, DATE_TRUNC(tmst, MONTH) month, IF(SUM(flag) > 0, 1, 0) flag
FROM sample_table
GROUP BY 1, 2
)
SELECT id, ANY_VALUE(flag) flag,
MIN(month) start_month,
IF(MAX(month) = ANY_VALUE(max_month), '9999-12-01', MAX(month)) end_month
FROM (
SELECT * EXCEPT(gap), COUNTIF(gap) OVER w1 AS part FROM (
SELECT *, flag <> LAG(flag) OVER w0 AS gap, MAX(month) OVER w0 AS max_month
FROM aggregation
WINDOW w0 AS (PARTITION BY id ORDER BY month)
) WINDOW w1 AS (PARTITION BY id ORDER BY month)
)
GROUP BY 1, part;
Query results