I have a csv file structured like this:
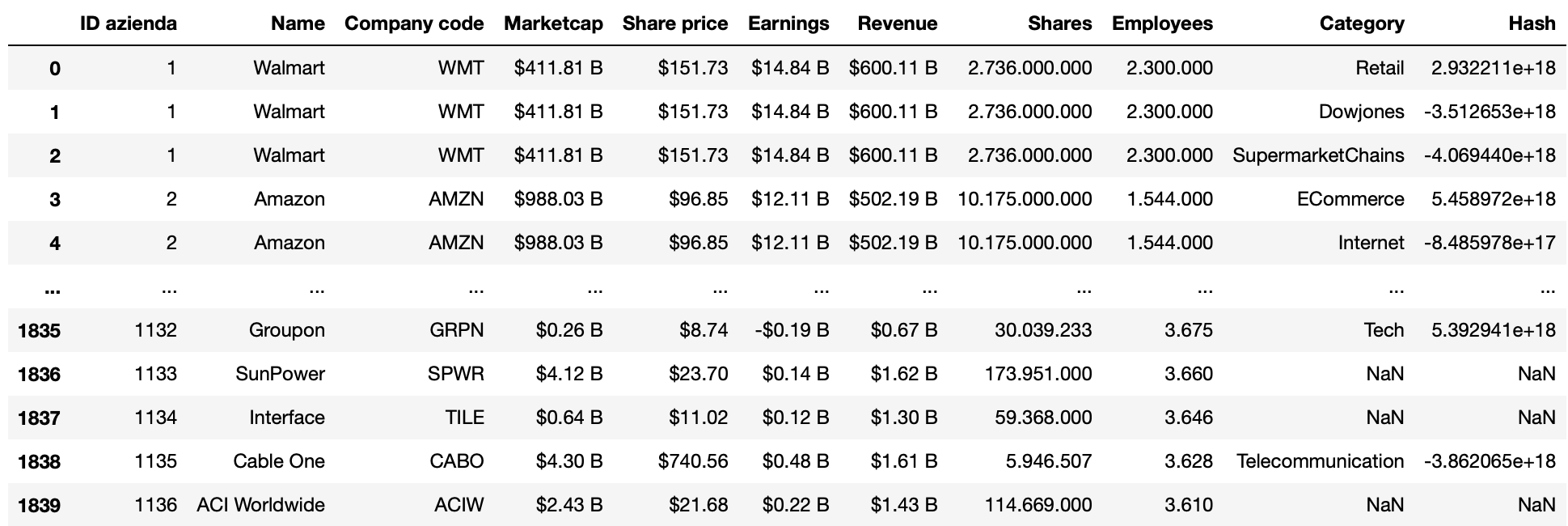
As you can see, many lines are repeated (they represent the same entity) with the attribute 'category' being the only difference between each other. I would like to join those rows and include all the categories in a single value.
For example the attribute 'category' for Walmart should be: "Retail, Dowjones, SuperMarketChains".
Edit:
I would like the output table to be structured like this:

CodePudding user response:
Quick and Dirty
df2=df.groupby("Name")['Category'].apply(','.join)
subst=dict(df2)
df['category']=df['Name'].replace(subst)
df.drop_duplicates('Name')
if you prefer multiple categories to be stored as a list in pandas column category... change first line to
df2=df.groupby("Name")['Category'].apply(list)
CodePudding user response:
Not sure if you want a new table or just a list of the categories. Below is how you could make a table with the hashes if those are important
import pandas as pd
df = pd.DataFrame({
'Name':['W','W','W','A','A','A'],
'Category':['Retail','Dow','Chain','Ecom','Internet','Dow'],
'Hash':[1,2,3,4,5,6],
})
# print(df)
# Name Category Hash
# 0 W Retail 1
# 1 W Dow 2
# 2 W Chain 3
# 3 A Ecom 4
# 4 A Internet 5
# 5 A Dow 6
#Make a new df which has one row per company and one column per category, values are hashes
piv_df = df.pivot(
index = 'Name',
columns = 'Category',
values = 'Hash',
)
# print(piv_df)
# Category Chain Dow Ecom Internet Retail
# Name
# A NaN 6.0 4.0 5.0 NaN
# W 3.0 2.0 NaN NaN 1.0