In the pandas 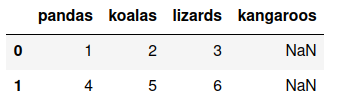
whereas based on their explanation, I would have expected Pandas to use the pandas column as the index since the number of fields in the column header is larger than the number of fields in the remaining lines. What am I missing here?
CodePudding user response:
It's ambiguous, but the "it" in "If it is larger" refers to the number of fields in the body of the data file rather than number of column header fields. If you had a CSV file named foo2.csv with the contents
pandas, koalas
1,2,3
4,5,6
then "1" and "4" would be used as the indices of the rows in the body, so running pd.read_csv("foo2.csv") would get you this:
pandas koalas
1 2 3
4 5 6