Problem Summary
- I'm trying to load .txt files in Python using Pandas.
- The .txt files uses | delimiter between fields
- Each field is captured between double quotes "" as a string: e.g. "i_am_a_string"
- The problem is some fields have apostrophes represented with double quotes. e.g. "I"m_not_a_valid_string" (it should be "I'm_not_a_valid_string")
Sample file
To demonstrate my issue I have created a test file which is as follows when edited in vi:
"Name"|"Surname"|"Address"|"Notes"^M
"Angelo"|""|"Kenton Square 5"|"Note 1"^M
"Angelo"|""|"Kenton’s ^M
Sqr5"|"note2"^M
"Angelo"|""|"Kenton"s ^M
Road"|"Note3"^M
Loading data
To load this file I run the following command in Jupyter notebook:
test = pd.read_csv('test.txt', sep ='|')
which loads up the file like the screenshot below:
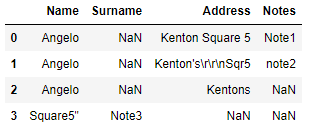
Questions
There's 2 issues I'm looking to address represented in examples "note2" and and "Note3" in the file:
note2 question
How can I get rid of the ^M when loading the file? i.e. how can I remove the "\r\r\n" from the Address column when loaded up in Jupyter. The "note2" example should have loaded like this in the Address column:
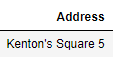
- Should I remove these before loading the file using bash commands or
- Should I remove these after I load it in Jupyter using Python?
- Can you please suggest the code to do it in each case and which one would you recommend (and why)?
Note3 question
How do I replace the double quote within the string expression with apostrophe? here it breaks it to another line which is incorrect. This should be loaded in row 2 as follows:
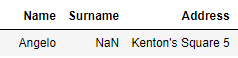
"Note3" example is a compounded one as it also has the "^M" characters in the string but here I'm interested in replacing the double quotes with an apostrophe so it doesn't break it to another line corrupting the loading.
Thank you for your help, much appreciated.
Angelo
CodePudding user response:
How do I replace the double quote within the string expression with apostrophe?
If " which are to be converted into ' are always between letters (word characters) you might preprocess your file using regular expression (re) following way
import re
txt = '''"Name"|"Surname"|"Address"|"Notes"
"Angelo"|""|"Kenton Square 5"|"Note 1"
"Angelo"|""|"Kenton’s
Sqr5"|"note2"
"Angelo"|""|"Kenton"s
Road"|"Note3"'''
clean_text = re.sub(r'(?<=\w)"(?=\w)', "'", txt)
print(clean_text)
output
"Name"|"Surname"|"Address"|"Notes"
"Angelo"|""|"Kenton Square 5"|"Note 1"
"Angelo"|""|"Kenton’s
Sqr5"|"note2"
"Angelo"|""|"Kenton's
Road"|"Note3"
Explanation: use zero-length assertion to find " which are after word character and before word character.
If you have text in file, firstly read it as text file i.e.
with open("test.txt","r") as f:
txt = f.read()
then clean it
import re
clean_text = re.sub(r'(?<=\w)"(?=\w)', "'", txt)
then put it into pandas.DataFrame using io.StringIO as follows
import io
import pandas as pd
test = pd.read_csv(io.StringIO(clean_text), sep ='|')