I have a problem that sounds easy, however, I could not find a solution in R. I would like to shift values according to the first year of the release. I mean the first column represents the years of the release and the columns are years when the device is broken (values are numbers of broken devices).
This is a solution in Python:
def f(x):
shifted = np.argmin((x.index.astype(int)< x.name[0]))
return x.shift(-shifted)
df = df.set_index(['Delivery Year', 'Freq']).apply(f, axis=1)
df.columns = [f'Year.{i 1}' for i in range(len(df.columns))]
df = df.reset_index()
df
I would like to have it in R too.
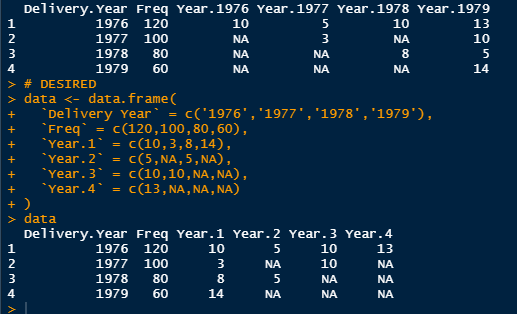
# TEST
data <- data.frame(
`Delivery Year` = c('1976','1977','1978','1979'),
`Freq` = c(120,100,80,60),
`Year.1976` = c(10,NA,NA,NA),
`Year.1977` = c(5,3,NA,NA),
`Year.1978` = c(10,NA,8,NA),
`Year.1979` = c(13,10,5,14)
)
data
# DESIRED
data <- data.frame(
`Delivery Year` = c('1976','1977','1978','1979'),
`Freq` = c(120,100,80,60),
`Year.1` = c(10,3,8,14),
`Year.2` = c(5,NA,5,NA),
`Year.3` = c(10,10,NA,NA),
`Year.4` = c(13,NA,NA,NA)
)
data
In addition, would it be also possible to transform the number of broken devices into the percentage of Freq column?
Thank you
CodePudding user response:
library(dplyr)
f <- function(df) {
years <- paste0("Year.",sort(as.vector(na.omit(as.integer(stringr::str_extract(colnames(df), "\\d "))))))
df1 <- df %>% select(years)
df2 <- df %>% select(-years)
val <- c()
firstyear <- years[1]
for (k in 1:nrow(df1) ) {
vec <- as.numeric(as.vector(df1[k,]))
val[k] <- (as.numeric(suppressWarnings(na.omit(vec))))[1]
}
df1[firstyear] <- val
colnames(df1) <- c(paste0("Year.",seq(1:ncol(df1))))
df <- cbind(df2,df1)
print(df)
}
> f(data)
Delivery.Year Freq Year.1 Year.2 Year.3 Year.4
1 1976 120 10 5 10 13
2 1977 100 3 3 NA 10
3 1978 80 8 NA 8 5
4 1979 60 14 NA NA 14
CodePudding user response:
Using tidyverse
data %>%
pivot_longer(!c(Delivery.Year, Freq)) %>%
separate(name, c("Lab", "Year")) %>%
select(-Lab) %>%
mutate_all(as.numeric) %>%
filter(Year >= Delivery.Year) %>%
group_by(Delivery.Year, Freq) %>%
mutate(ind = paste0("Year.", row_number()),
per = value/Freq) %>%
ungroup() %>%
pivot_wider(id_cols = c(Delivery.Year, Freq), names_from = ind, values_from = c(value, per))
I pivoted it into long form to begin with and separated the original column names Year.1976, Year.1977, etc. to just get the years from the columns and dropped the Year piece of it. Then I converted all columns to numeric to allow for mathematical operations like filtering for when Year >= Delivery.Year. I then created a column to get the titles you did request Year.1, Year.2, etc. and calculated the percent. Then I pivot_wider to get it in the format you requested. One thing to note is that I was unclear if you wanted both the original values and the percent or just the percent. If you only want the percent then values_from = per should do it for you.