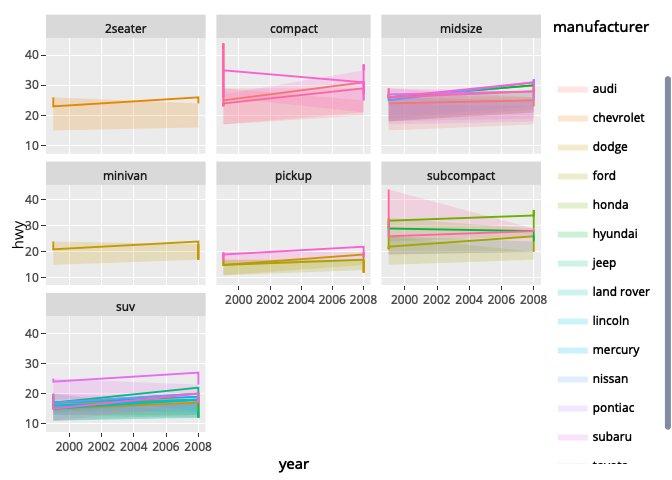
Consider the plot produced by the following reprex. Note that the ggplot has sensible legends, while in plotly, the legend is heavily duplicated, with one entry for each time the same category ("manufacturer") appears in each facet. How do I make the plotly legend better match that of the ggplot2 one?
library(plotly)
library(ggplot2)
p <- mpg %>%
ggplot(aes(year))
geom_ribbon(aes(ymin=cty, ymax=hwy, fill = manufacturer), alpha=0.2)
geom_line(aes(y = hwy, col=manufacturer))
facet_wrap(~class)
p
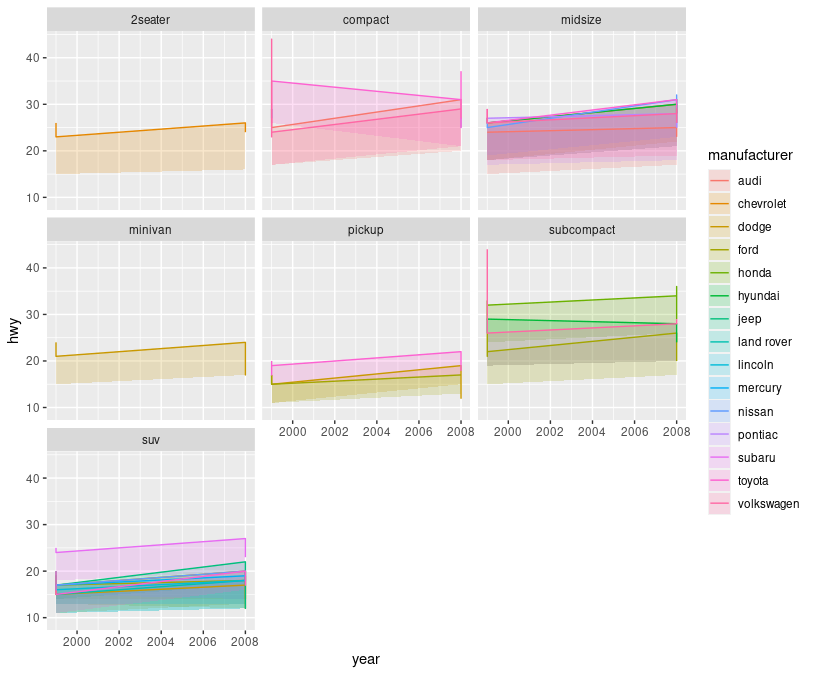
plotly::ggplotly(p)
CodePudding user response:
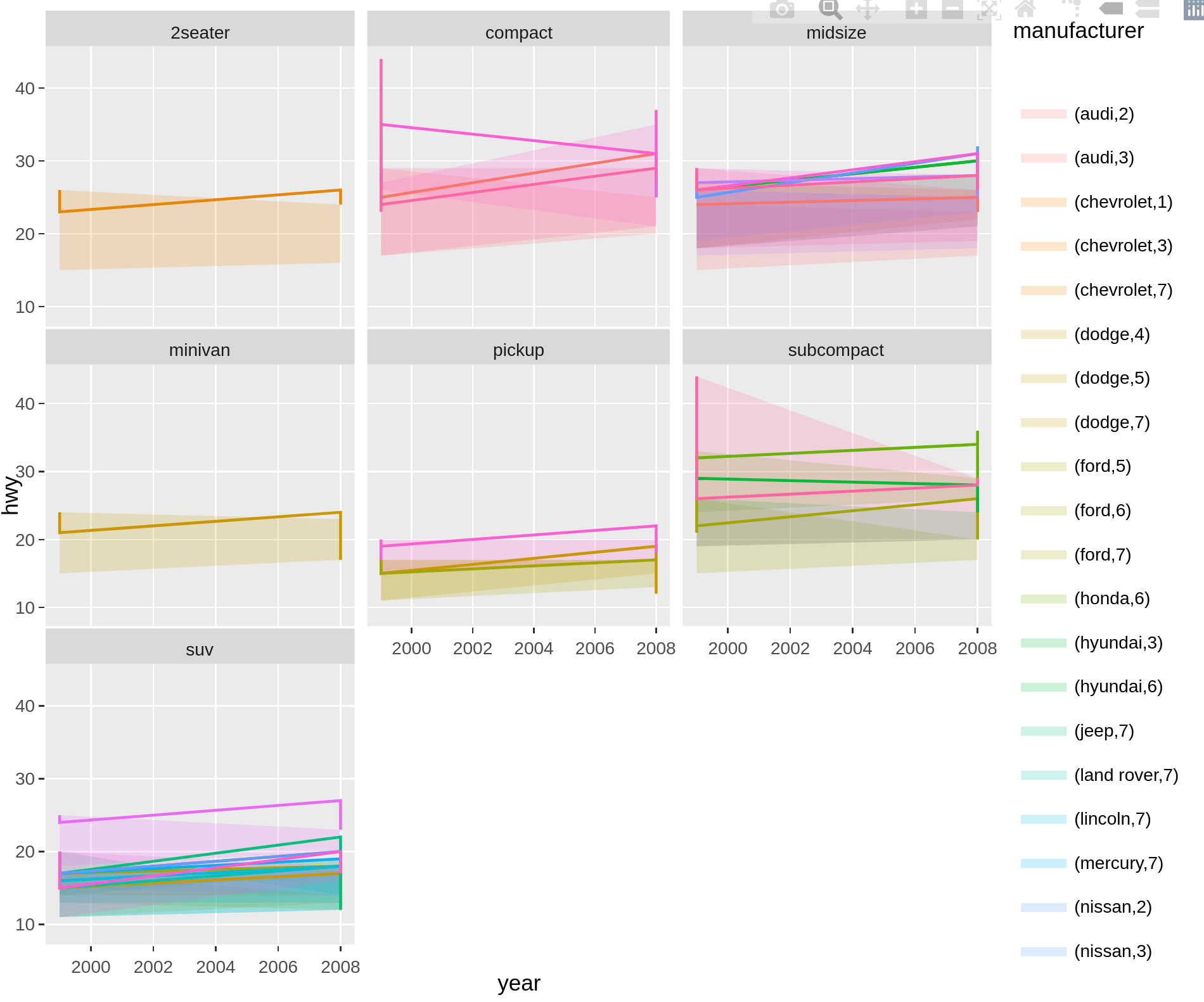
Adapting my answer on this post to your case (which draws on this answer) one option would be to manipulate the plotly object.
The issue is that with facetting we end up with one legend entry for each facet in which a group is present, i.e. the numbers in the legend entries correspond to the number of the facet or panel.
In plotly one could prevent the duplicated legend entries via the legendgroup argument. One option to achieve the same result when using ggplotly would be to assign the legendgroup manually like so:
library(plotly)
library(ggplot2)
p <- mpg %>%
ggplot(aes(year))
geom_ribbon(aes(ymin=cty, ymax=hwy, fill = manufacturer), alpha=0.2)
geom_line(aes(y = hwy, col=manufacturer))
facet_wrap(~class)
gp <- ggplotly(p = p)
# Get the names of the legend entries
df <- data.frame(id = seq_along(gp$x$data), legend_entries = unlist(lapply(gp$x$data, `[[`, "name")))
# Extract the group identifier
df$legend_group <- gsub("^\\((.*?),\\d \\)", "\\1", df$legend_entries)
# Add an indicator for the first entry per group
df$is_first <- !duplicated(df$legend_group)
for (i in df$id) {
# Is the layer the first entry of the group?
is_first <- df$is_first[[i]]
# Assign the group identifier to the name and legendgroup arguments
gp$x$data[[i]]$name <- df$legend_group[[i]]
gp$x$data[[i]]$legendgroup <- gp$x$data[[i]]$name
# Show the legend only for the first layer of the group
if (!is_first) gp$x$data[[i]]$showlegend <- FALSE
}
gp