I have a sample dataframe as given below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID':['A', 'A', 'A', 'B','B','B'],
'Date':['2021-09-20 04:34:57', '2021-09-20 04:37:25', '2021-09-20 04:38:26', '2021-09-01
00:12:29','2021-09-01 11:20:58','2021-09-02 09:20:58'],
'Name':['xx',NaN,NaN,'yy',NaN,NaN],
'Height':[174,NaN,NaN,160,NaN,NaN],
'Weight':[74,NaN,NaN,58,NaN,NaN],
'Gender':[NaN,'Male',NaN,NaN,'Female',NaN],
'Interests':[NaN,NaN,'Hiking,Sports',NaN,NaN,'Singing']}
df1 = pd.DataFrame(data)
df1
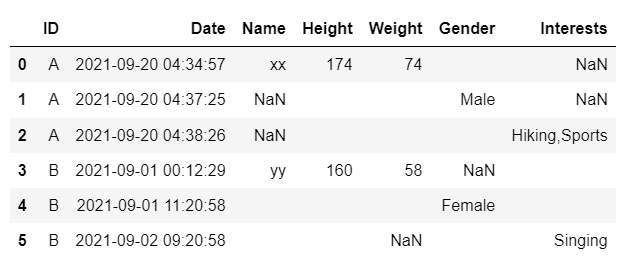 I want to combine the data present on the same date into a single row. The 'Date' column is in timestamp format.
The final output should look like the image shown below.
I want to combine the data present on the same date into a single row. The 'Date' column is in timestamp format.
The final output should look like the image shown below.
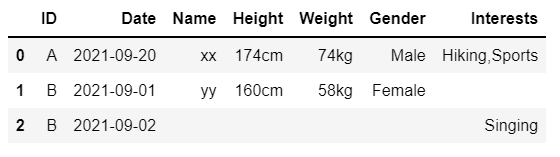
Any help is greatly appreciated. Thanks.
CodePudding user response:
New Solution
The old solution was based on initial version of question where empty strings instead of NaN values were used for undefined values and all columns were of string types. With updated question using NaN for undefined values (and even when also updated to have different column data types of numeric and string types), the solution can be simplified as follows:
You can use .groupby() GroupBy.last() to group by ID and date (without time) and then aggregate the NaN and non-NaN elements with the latest (asssuming column Date is presented in chronological order) non-NaN values for an ID, as follows:
# Convert `Date` to datetime format
df1['Date'] = pd.to_datetime(df1['Date'])
# Sort `df1` with ['ID', 'Date'] order if not already in this order
#df1 = df1.sort_values(['ID', 'Date'])
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.last()
.reset_index()
).replace([None], [np.nan])
Result:
print(df_out)
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female NaN
2 B 2021-09-02 NaN NaN NaN NaN Singing
Old Solution
You can use .groupby() .agg() to group by ID and date and then aggregate the NaN and non-NaN elements, as follows:
# Convert `Date` to datetime format
df1['Date'] = pd.to_datetime(df1['Date'])
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg(lambda x: ''.join(x.dropna().astype(str)))
.reset_index()
).replace('', np.nan)
Result:
print(df_out)
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female NaN
2 B 2021-09-02 NaN NaN NaN NaN Singing
As your original question had all columns of string types, the above codes work fine to give results of all columns as string types. However, your edited question has data with both numeric and string types. In order to retain the original data types, we can modify the codes as follows:
# Convert `Date` to datetime format
df1['Date'] = pd.to_datetime(df1['Date'])
df_out = (df1.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg(lambda x: np.nan if len(w:=x.dropna().reset_index(drop=True)) == 0 else w)
.reset_index()
)
Result:
print(df_out)
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174.0 74.0 Male Hiking,Sports
1 B 2021-09-01 yy 160.0 58.0 Female NaN
2 B 2021-09-02 NaN NaN NaN NaN Singing
print(df_out.dtypes)
ID object
Date datetime64[ns]
Name object
Height float64 <==== retained as numeric dtype
Weight float64 <==== retained as numeric dtype
Gender object
Interests object
dtype: object
CodePudding user response:
Start first by converting to datetime and flooring:
In [3]: df["Date"] = pd.to_datetime(df["Date"]).dt.floor('D')
In [4]: df
Out[4]:
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174cm 74kg
1 A 2021-09-20 Male
2 A 2021-09-20 Hiking,Sports
3 B 2021-09-01 yy 160cm 58kg
4 B 2021-09-01 Female
5 B 2021-09-02 Singing
Now using groupby and sum:
In [5]: df.groupby(["ID", "Date"]).sum().reset_index()
Out[5]:
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174cm 74kg Male Hiking,Sports
1 B 2021-09-01 yy 160cm 58kg Female
2 B 2021-09-02 Singing
CodePudding user response:
If your data are correctly ordered as your sample, you can merge your data as below:
>>> df1.groupby(['ID', pd.Grouper(key='Date', freq='D')]) \
.sum().reset_index()
ID Date Name Height Weight Gender Interests
0 A 2021-09-20 xx 174cm 74kg Male Hiking,Sports
1 B 2021-09-01 yy 160cm 58kg Female
2 B 2021-09-02 Singing