I am trying to pull and find the mean of Yi0 data if V1 = 0, and the mean of Yi1 data if V1=1, for each Vx (V1...V2 etc) column, but my code seems to flawed, does anyone has suggestions on how I could fix this?
This is my sample data and code
set.seed(1)
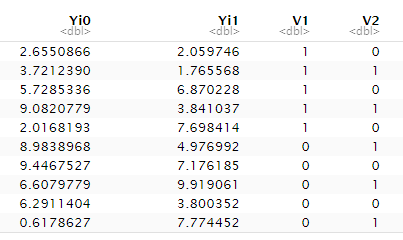
df <- data.frame(Yi0 = runif(n=10, min = 0, max = 10),
Yi1 = runif(n=10, min = 0, max = 10),
V1 = c(1,1,1,1,1,0,0,0,0,0),
V2 = c(0,1,0,1,0,1,0,1,0,1))
pm <- function(x) {
as.numeric(
ifelse(
test = df[,x] == 0,
yes =mean(df["Yi0"]),
no = ifelse(
test = df[,x] == 1,
yes = mean(df["Yi1"]),
no = "error")))
}
ab <- sapply(X = 3:4, FUN=pm)
ab
Ultimately, I will want to take mean(2.059 1.765 ... 7.69) - mean(8.9838 9.446 ... 0.6178), for each of the column starting with V, I have a total of 2 million of them...
thank you
this is the original data set
CodePudding user response:
If I understand you correctly, for one column (V1) you want to do
mean(df$Yi0[df$V1 == 0]) - mean(df$Yi1[df$V1 == 1])
#[1] 1.9
For multiple columns using sapply you can do -
sapply(df[3:4], function(x) mean(df$Yi0[x == 0]) - mean(df$Yi1[x == 1]))
# V1 V2
# 1.94 -0.43
CodePudding user response:
Based on the updated post, we can reshape to 'long' with pivot_longer and take the difference in mean
library(dplyr)
library(tidyr)
df %>%
pivot_longer(cols = V1:V2) %>%
group_by(name) %>%
summarise(Diff = mean(Yi0[value == 0]) - mean(Yi1[value == 1]))
-output
# A tibble: 2 × 2
name Diff
<chr> <dbl>
1 V1 1.94
2 V2 -0.428
If there are many columns, an efficient approach would be to use collapse
library(collapse)
dapply(get_vars(df, vars = "^V\\d ", regex = TRUE), MARGIN = 2,
FUN = function(x) fmean(df$Yi0[!x] - fmean(df$Yi1[x == 1])))
V1 V2
1.9425275 -0.4277555