I have a data frame col contains a range of cost centre value strings.
A6652 - A6670
I want to achieve in the next col to split them up as
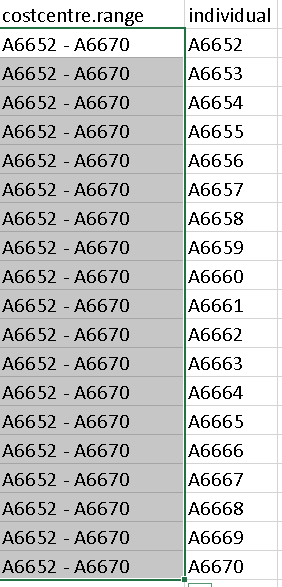
How can I do it in R?
CodePudding user response:
A simple solution is this:
# your data
df <- data.frame(costcentre.range = rep("A6652 - A6670", 19))
# solution
library(stringr) # required for `str_extract()`
df$individual <- paste0(
"A", as.integer(str_extract(df$costcentre.range, "\\d ")) 0:(nrow(df)-1))
A more complex solution, say, if the costcentre.range doesn't always start with "A" or you have a second set of ranges, can look like this:
# data with "A66##" and "B77##" individuals
df2 <- data.frame(
costcentre.range = c(rep("A6651 - A6660", 10), rep("B7781 - B7790", 10)))
# solution
library(dplyr)
library(stringr)
library(tidyr)
df2 <- df2 %>%
mutate(first_id = str_extract(costcentre.range, "[A-Z]\\d ")) %>%
separate(first_id, c("letter", "number"), "(?<=[A-Z])(?=\\d )", convert = TRUE) %>%
group_by(costcentre.range) %>%
mutate(number = number 0:(n()-1)) %>%
unite(individual, letter, number, sep = "")
df2
## A tibble: 20 x 2
## Groups: costcentre.range [2]
# costcentre.range individual
# <fct> <chr>
# 1 A6651 - A6660 A6651
# 2 A6651 - A6660 A6652
# 3 A6651 - A6660 A6653
# 4 A6651 - A6660 A6654
# 5 A6651 - A6660 A6655
# 6 A6651 - A6660 A6656
# 7 A6651 - A6660 A6657
# 8 A6651 - A6660 A6658
# 9 A6651 - A6660 A6659
#10 A6651 - A6660 A6660
#11 B7781 - B7790 B7781
#12 B7781 - B7790 B7782
#13 B7781 - B7790 B7783
#14 B7781 - B7790 B7784
#15 B7781 - B7790 B7785
#16 B7781 - B7790 B7786
#17 B7781 - B7790 B7787
#18 B7781 - B7790 B7788
#19 B7781 - B7790 B7789
#20 B7781 - B7790 B7790
The first goal is to extract the first ID string in the range values (str_extract()).
Then separate the letter values from the number values so that you can treat the number values as integers (separate()),
which you can then use addition to change the numbers (mutate(number = ...)).
Note that group_by(costcentre.range) and n() together give you the group sizes of the unique values in costcentre.range.
Finally, unite the letters and the new numbers back together again, forming the new column (unite()).
CodePudding user response:
Using data from @LC-datascientist post here is a tidyverse way to do this.
Keep only unique rows in the data, split the costcentre.range into two columns (start and end), create a sequence between them and unnest the data in long format.
library(tidyverse)
df2 <- data.frame(
costcentre.range = c(rep("A6651 - A6660", 10), rep("B7781 - B7790", 10)))
df2 %>%
distinct() %>%
separate(costcentre.range, c('start', 'end'), sep = '\\s-\\s') %>%
mutate(group = sub('([A-Z] ).*', '\\1', start),
across(c(start, end), .fns = parse_number),
individual = map2(start, end, seq)) %>%
unnest(individual) %>%
unite(individual, group, individual, sep = '') %>%
select(individual)
This returns -
# individual
# <chr>
# 1 A6651
# 2 A6652
# 3 A6653
# 4 A6654
# 5 A6655
# 6 A6656
# 7 A6657
# 8 A6658
# 9 A6659
#10 A6660
#11 B7781
#12 B7782
#13 B7783
#14 B7784
#15 B7785
#16 B7786
#17 B7787
#18 B7788
#19 B7789
#20 B7790