Here's my code:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import pandas as pd
import matplotlib as mpl
import numpy as np
import matplotlib.pyplot as plt
#create a list of each year where data will be extract
years_list = [2001, 2002, 2008, 2012, 2015,2018, 2020 , 2021]
player_list = ['Mac Jones', 'Aaron Rodgers', 'Deshaun Watson', 'Patrick Mahomes',
'Josh Allen', 'Ryan Tannehill', 'Drew Bress', 'Russel Wilson',
'Kirk Cousins', 'Tom Brady', 'Derek Carr']
#selecting stats
cols = ['Player', 'Tm','Cmp%', 'Yds', 'TD', 'Int', 'Y/A', 'Rate', 'G']
df_list = []
#loop for extract data
for year in years_list:
url_mac = f'https://www.pro-football-reference.com/years/{year}/passing.htm'
temp_df = pd.read_html(url_mac)[0][cols]
temp_df['Season'] = year
df_list.append(temp_df)
print(f'Collected: {year}')
data_radar = pd.concat(df_list)
#renaming columns
new_columns = data_radar.columns.values
new_columns[-6] = 'y_sack'
data_radar.columns = new_columns
#picking stats
mid_data = pd.DataFrame()
for player in player_list:
mid_data = mid_data.append(data_radar[data_radar['Player'] == player '*'])
mid_data = mid_data.append(data_radar[data_radar['Player'] == player '*' ' '])
mid_data = mid_data.append(data_radar[data_radar['Player'] == player])
mid_data = mid_data.append(data_radar[data_radar['Player'] == player ' '])
#relevant stats
cols = ['Cmp%', 'Yds', 'Int', 'Y/A','Rate', 'G', 'Season']
final_data = pd.DataFrame()
#fixing names
mid_data = mid_data.replace({'Tom Brady*':'Tom Brady', 'Aaron Rodgers*':'Aaron Rodgers','Aaron Rodgers* ':'Aaron Rodgers',
'Deshaun Watson*':'Deshaun Watson', 'Josh Allen*':'Josh Allen',
'Derek Carr*':'Derek Carr','Patrick Mahomes*':'Patrick Mahomes', 'Patrick Mahomes* ':'Patrick Mahomes' })
#Select informations about players and ordering
final_data = mid_data[['Player', 'Tm'] cols]
final_data.sort_values(by = 'Player', ascending=True)
final_data.drop_duplicates(subset = 'Player')
What i want with that code is that my df final_data returns me first season of each player, but that dont work with some players that i needed use replace method.
Where i write to sort_value that's my result, before drop.duplicates()
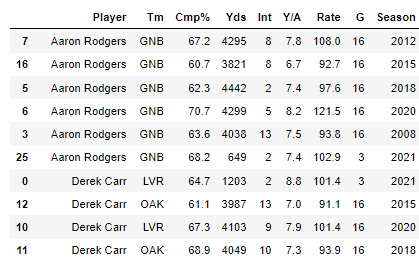
My idea was sort these values, then use drop.duplicates() to select just first of each player.
This happen with all players that i needed use replace method. How fix this ?
CodePudding user response:
There's quite a few confusing parts of your code. First, if all you are trying to do is get rid of the '*' and or ' ' in the player names, why not just do that as opposed to hard coding each player? Second, your comments don't actually describe what your code is doing. I don't see the point of
#Converting colums from object to floats
cols = ['Cmp%', 'Yds', 'Int', 'Y/A','Rate', 'G', 'Season']
final_data = pd.DataFrame()
as you are not converting to floats, and # picking top 10 qb in rating stats in last season Mac Jones comment isn't doing what it says either. Very confusing to follow your comments.
Thirdly, if you want the first season of each player, then you need to sort by 'Season', so when you drop duplicates of the player name, you can explicitly say to keep the first entry/row of that player, which wil be their first season in the dataframe if you sorted it.
Try this:
import pandas as pd
#create a list of each year where data will be extract
years_list = [2001, 2002, 2008, 2012, 2015,2018, 2020 , 2021]
player_list = ['Mac Jones', 'Aaron Rodgers', 'Deshaun Watson', 'Patrick Mahomes',
'Josh Allen', 'Ryan Tannehill', 'Drew Bress', 'Russel Wilson',
'Kirk Cousins', 'Tom Brady', 'Derek Carr']
#selecting stats
cols = ['Player', 'Tm','Cmp%', 'Yds', 'TD', 'Int', 'Y/A', 'Rate', 'G']
df_list = []
#loop for extract data
for year in years_list:
url_mac = f'https://www.pro-football-reference.com/years/{year}/passing.htm'
temp_df = pd.read_html(url_mac)[0][cols]
temp_df['Season'] = year
temp_df = temp_df[temp_df['Player'] != 'Player']
df_list.append(temp_df)
print(f'Collected: {year}')
data_radar = pd.concat(df_list)
#renaming columns
new_columns = data_radar.columns.values
new_columns[-6] = 'y_sack'
data_radar.columns = new_columns
# Repace * or with ''
data_radar['Player'] = data_radar['Player'].str.replace(r'\*|\ ','')
cols = ['Cmp%', 'Yds', 'Int', 'Y/A','Rate', 'G', 'Season']
#Select informations about players and ordering
final_data = data_radar[['Player', 'Tm'] cols]
final_data = final_data.sort_values(by = ['Player', 'Season'], ascending=[True,True])
final_data = final_data.drop_duplicates(subset = 'Player', keep='first')
Output:
print(final_data)
Player Tm Cmp% Yds Int Y/A Rate G Season
53 A.J. Feeley PHI 71.4 143 1 10.2 114.0 1 2001
41 A.J. McCarron CIN 66.4 854 2 7.2 97.1 7 2015
3 Aaron Brooks NOR 55.9 3832 22 6.9 76.4 16 2001
3 Aaron Rodgers GNB 63.6 4038 13 7.5 93.8 16 2008
71 Akili Smith CIN 62.5 37 0 4.6 73.4 2 2001
.. ... ... ... ... .. ... ... .. ...
89 Wayne Chrebet NYJ 0.0 0 0 0.0 39.6 15 2002
39 Zach Mettenberger TEN 60.8 935 7 5.6 66.7 7 2015
112 Zach Pascal IND 0.0 0 0 0.0 39.6 16 2020
27 Zach Wilson NYJ 55.2 628 7 6.0 51.6 3 2021
105 Zay Jones BUF 0.0 0 0 0.0 39.6 16 2018
[427 rows x 9 columns]