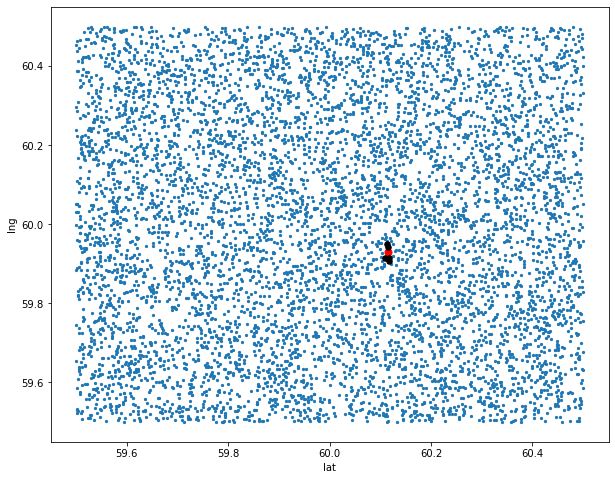
Currently, I use the following code to find the closest given geopoint -
def get_closest_stops(lat, lng, data=db.STOPS):
def distance(lat1, lon1, lat2, lon2):
p = 0.017453292519943295
a = 0.5 - cos((lat2-lat1)*p)/2 cos(lat1*p)*cos(lat2*p) * (1-cos((lon2-lon1)*p)) / 2
return 12742 * asin(sqrt(a))
v = {'lat': lat, 'lng': lng}
return sorted(data.values(), key=lambda p: distance(v['lat'],v['lng'],p['lat'],p['lng']), reverse=False)
and here is the db.STOPS:
STOPS = {
'1282': {'lat': 59.773368, 'lng': 30.125112, 'image_osm': '1652229/464dae0763a8b1d5495e', 'name': 'name 1', 'descr': ''},
'1285': {'lat': 59.941117, 'lng': 30.271756, 'image_osm': '965417/63af068831d93dac9830', 'name': 'name 2', 'descr': ''},
...
}
The dict contains about 7000 records and the search is slow. Is there any way to speed up the search? I need just 5 results. And I can re-sort the dict. I can even create a copy of the dict, if needed.
CodePudding user response:
Use Multithreading, and break the record into the number of threads available
CodePudding user response:
Sorry for the late answer - I kind of stuck debugging an issue caused by a typo.
TLDR: numpy gives 10x speedup, partitioning distances speeds up by another 3x, ~30..50x total. Using manhattan distance as a cheaper approximation to eliminate infeasible candidates has about the same effect, but is less intuitive.
Here is a