I have the following dataframe:
d = {'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
'value': [10, 8, 7, 7, 0, 2, 9, 4, 0, 9, 10, 4, 5, 5],
'box': [1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2],
'fruit': ['apple', 'apple', 'apple', 'lime', 'lime', 'orange',
'orange', 'lime', 'orange', 'apple', 'apple', 'apple',
'orange', 'orange']
}
dummy_df = pd.DataFrame(d)
I would like to create a column with standardized values, with conditions: I want to standardize the values by box column, but use the values for calculating the mean and the standard deviation from only the apple items. So instead of using the mean (box1_mean: 6.14, box2_mean: 5.28) and std (box1_std: 3.71, box2_std: 3.35) of each box, I would like to use only the "apple" values to calculate it (box1_apple_mean: 8.33, box1_apple_std: 1.52, box2_apple_mean: 7.66, box2_apple_std: 3.21).
Desired output would look like this:
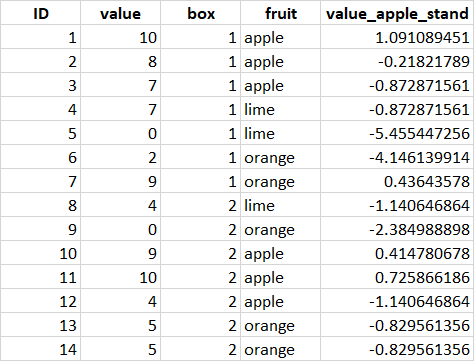
I have this line of code to perform the standardization by box, but this doesn't give me the desired output.
dummy_df['value_apple_stand'] = dummy_df.groupby('box')['value'].transform(lambda x: (x-x.mean())/x.std())
How to put the extra information to take into account in calculating the mean and std from only the values where fruit is apple?
Thank you in advance!
CodePudding user response:
Use apply instead of transform. With apply you have access to all columns which you can use to filter and calculate mean and std for specific conditions:
def norm_by(g, fruit):
fruit_value = g['value'][g['fruit'] == fruit]
return (g.value - fruit_value.mean()) / fruit_value.std()
dummy_df['value_apple_stand'] = \
dummy_df.groupby('box', group_keys=False).apply(norm_by, 'apple')
dummy_df
ID value box fruit value_apple_stand
0 1 10 1 apple 1.091089
1 2 8 1 apple -0.218218
2 3 7 1 apple -0.872872
3 4 7 1 lime -0.872872
4 5 0 1 lime -5.455447
5 6 2 1 orange -4.146140
6 7 9 1 orange 0.436436
7 8 4 2 lime -1.140647
8 9 0 2 orange -2.384989
9 10 9 2 apple 0.414781
10 11 10 2 apple 0.725866
11 12 4 2 apple -1.140647
12 13 5 2 orange -0.829561
13 14 5 2 orange -0.829561
CodePudding user response:
to have the mean of the value_apple_stand where fruit is equal to apple, you can do this;
df.loc[df['fruit'] == 'apple', 'value_apple_stand'].mean()
Otherwhise, applying a lambda function, to have the mean() for each type of fruit:
df.groupby(['fruit']).apply(lambda x: x['value_apple_stand'].mean())