So I have a really big dataframe with the following information:
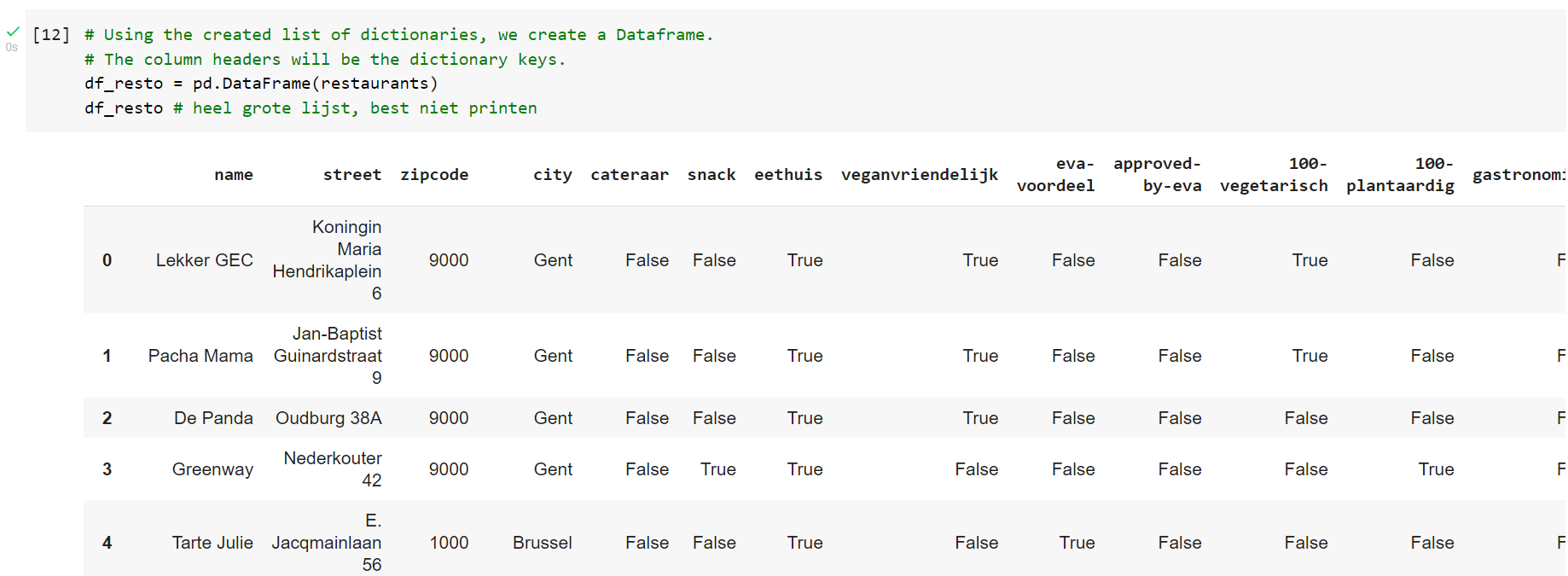
There are 2 columns "eethuis" and "caternaar" which return True or False whether they have it or not. Now I need to find the number of places where they have both eethuis and caternaar. So this means that I need to count the rows where eethuis and caternaar return True. But I can't really find a way? Even after searching for sometime. This is what I have. I merged the 2 rows that I need togheter but now I still need to select and count the columns that are both True:
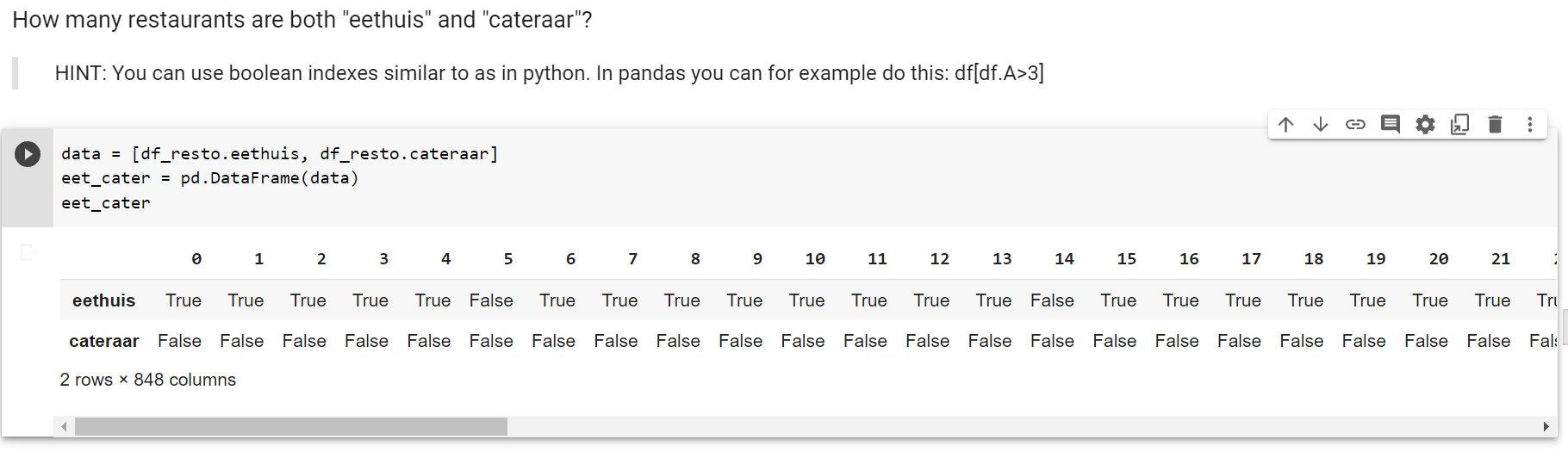
In the picture You will not see a column where both are true, but there are some. Its a really long table with over 800 columns.
Would be nice if someone could help me!
CodePudding user response:
If I understand your question correctly, you can use '&', here is an example on random data:
import pandas as pd
import random
# create random data
df = pd.DataFrame()
df['col1'] = [random.randint(0,1) for x in range(10000)]
df['col2'] = [random.randint(0,1) for x in range(10000)]
df = df.astype(bool)
# filter it:
df1 = df[(df['col1']==True) & (df['col2']==True)]
# check sise:
df1.shape
CodePudding user response:
Thanks to Ezer K I found the solution! Here is the code:
totaal = df_resto[(df_resto['eethuis']==True) & (df_resto['cateraar']==True)]
This is the output:
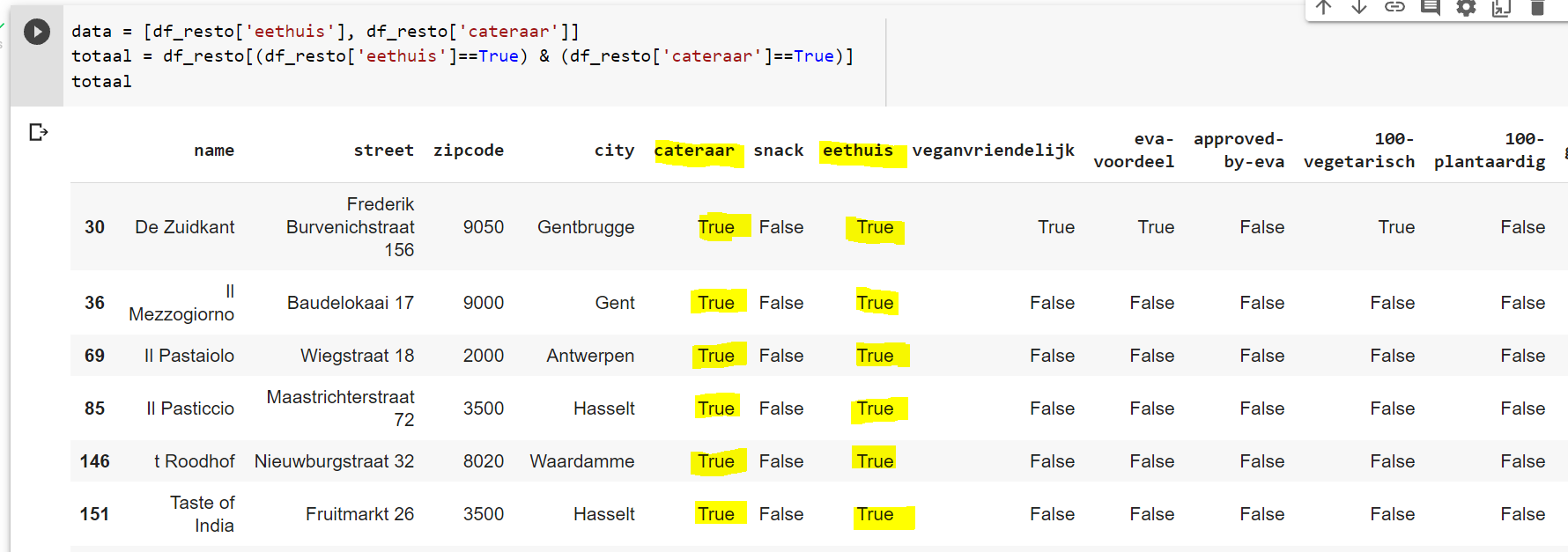 `
`
So u see it works!
And the count is 41!
