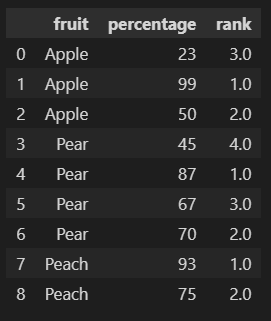
For the table below, consider just the first 2 columns 'Fruit' and 'percentage'.
How do you add a third column, ie. 'new_column' that looks at the 'Fruit' column in groups and puts a number corrosponding to the percentage. For example, in the 'Apple' group - the highest percentage is 99 - so it is assigned 1....and so on.
So - given the 'Fruit' and 'percentage' column - how do you then add 'new_column' to the dataframe.
Hope this is clear and thankyou in advance.
| Fruit | percentage | new_column |
|---|---|---|
| Apple | 23 | 3 |
| Apple | 99 | 1 |
| Apple | 50 | 2 |
| Pear | 45 | 4 |
| Pear | 87 | 1 |
| Pear | 67 | 3 |
| Pear | 70 | 2 |
| Peach | 93 | 1 |
| Peach | 75 | 2 |
CodePudding user response:
I think this should be like this:
import pandas as pd
Original data:
df = pd.DataFrame({
'fruit': ['Apple', 'Apple', 'Apple', 'Pear', 'Pear', 'Pear', 'Pear', 'Peach', 'Peach'],
'percentage': [23, 99, 50, 45, 87, 67, 70, 93, 75]
})
Output
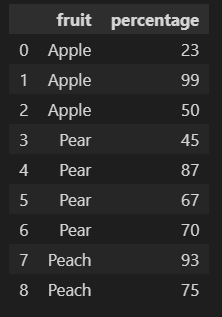
Create new 'rank' column based on grouping the df dataframe on fruit and rank the value of percentage within the group.
df['rank'] = df.groupby('fruit')['percentage'].rank()
Output: