I'm working with a food delivery dataset which contains the user_id and states where my clients have a registered address. Let's assume that the states that appers more often are the ones where the client lives and the others are places they visited or lived for a short period of time.
>>> ADDRESSES
USER_ID | STATE |
_______________________________________________
0 100 | ["AL", "AL", "AL"] |
1 101 | ["LA", "LA", "MI"] |
2 102 | ["NY", "NY", "KY", "NY", "NY"] |
3 103 | ["DE", "DE", "CO", "CO", "DE"] |
4 104 | ["CA"] |
5 105 | ["FL", "GA", "LA", "LA"] |
6 106 | ["ID", "ID", "ID", "DE"] |
7 107 | ["TX", "TX", "VT"] |
8 108 | ["RI"] |
9 109 | ["TN", "TN", "OK", "VA"] |
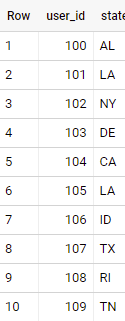
That being said, how can I get the most common state for each client so I can get the result bellow?
>>> ADDRESSES
USER_ID | STATE |
____________________
0 100 | AL |
1 101 | LA |
2 102 | NY |
3 103 | DE |
4 104 | CA |
5 105 | LA |
6 106 | ID |
7 107 | TX |
8 108 | RI |
9 109 | TN |
CodePudding user response:
Consider (BigQuery) below approach (assuming that state column is array of strings)
select user_id,
( select st from t.state st
group by st order by count(1) desc
limit 1 ) state
from your_table t
if applied to sample data in your question - output is
CodePudding user response:
There are no arrays in standard SQL. There might be such a thing in the DBMS you're using, but not in general.
What I see in
0 100 | ["AL", "AL", "AL"] |
is 2 columns: an integer, and a string. I'm guessing that's not really it; I'm guessing the tool you're using represents an "array" in your DBMS using Python syntax: [] to indicate an array, and "" to indicate strings. So an array 3 strings. But that's just a guess because you don't say.
The standard answer to your question is prefixed by don't do that. Since before SQL was invented, First Normal Form (1NF) proscribed repeating groups as a datatype. That is to say, the table is not in 1NF. To answer the question you asked with SQL as she is spoke, you first need to eliminate the repeating groups.
How? For that row, you need something like this:
0 100 | 1 | ["AL" |
0 100 | 2 | ["AL" |
0 100 | 3 | ["AL" |
How you get there, I don't know. It depends on what you actually have, and what your DBMS offers. But, once you're there, the query almost writes itself:
select X.user_id, min(X.state) as state
from (
select user_id, state, count(state) as N
from table_1nf
group by user_id, state ) as X
join
select user_id, max(N) as N
from (
select user_id, state, count(state) as N
from table_1nf
group by user_id, state ) as foo
) as T
on X.user_id = T.user_id and X.N = T.N
group by X.user_id
That query ensures that, in the event of a tie, you get only the first state having the highest count.