I have a DataFrame that looks like this. I am trying to add a new column df['new_sales'] where I multiply df['rate'] by the groupby sum of df['state','store'].
import pandas as pd
data = [['california', 'a', 11, 0.6], ['california', 'a', 12, 0.4], ['california', 'b', 32, 0.7]]
df= pd.DataFrame(data, columns=['state','store','sales','rate'])
I was trying something like this but couldn't get it to work.
df['new_sales'] = df.groupby(['state','store'])['sales'].apply(lambda x: x.sum()*df['rate'])
The output would look like this.
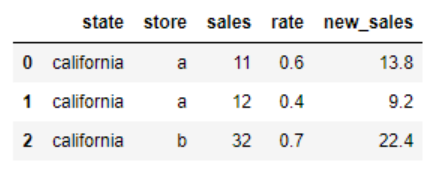
CodePudding user response:
1.without groupby
df = df.groupby(['state','store'])['sales'].apply(lambda x: x.sum()*df['rate'])
output:
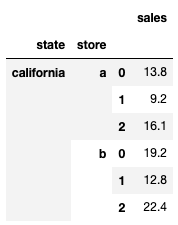
2.with groupby:
def doCalculation(df):
sales = df['sales'].sum()
rate = df['rate']
return sales * rate
df = df.groupby(['state','store']).apply(doCalculation)
output:
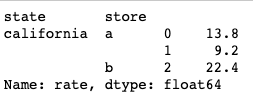
- newdf['NewSales'] = df.values
out:
CodePudding user response:
Use the transform option, to align the values with the length of the original dataframe; should be faster than an apply, and without the anonymous function :
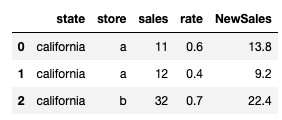
df['NewSales'] = df.groupby(['state', 'store']).sales.transform('sum') * df.rate
print(Df)
state store sales rate NewSales
0 california a 11 0.6 13.8
1 california a 12 0.4 9.2
2 california b 32 0.7 22.4