I have a sample dataframe as given below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID':['A','A','A','A','A','A','A','A','A','C','C','C','C','C','C','C','C'],
'Week': ['Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2','Week3',
'Week1','Week1','Week1','Week1','Week2','Week2','Week2','Week2'],
'Risk':['High','','','','','','','','','High','','','','','','',''],
'Testing':[NaN,'Pos',NaN,'Neg',NaN,NaN,NaN,NaN,'Pos', NaN,
NaN,NaN,'Negative',NaN,NaN,NaN,'Positive'],
'CloseContact': [NaN, 'True', NaN, NaN, 'False',NaN, NaN, 'False', 'True',
NaN, NaN, 'False', NaN, 'True','True','False', NaN ]}
df1 = pd.DataFrame(data)
df1
Now, 2 columns have to be created CC1 and CC2. For each ID, for each week(important), CC1 will get the first non null value of 'CloseContact' column and CC2 will get the second non null value of 'CloseContact' column.
The final dataframe should shoild look like the image shown below.
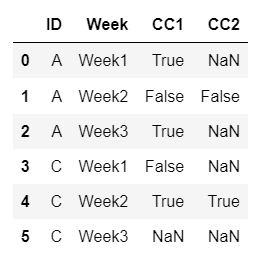
Any help is greatly appreciated. Thank you.
CodePudding user response:
Try:
import pandas as pd
import numpy as np
NaN = np.nan
data = {'ID': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C', 'C'],
'Week': ['Week1', 'Week1', 'Week1', 'Week1', 'Week2', 'Week2', 'Week2', 'Week2', 'Week3',
'Week1', 'Week1', 'Week1', 'Week1', 'Week2', 'Week2', 'Week2', 'Week2', 'Week3'],
'Risk': ['High', '', '', '', '', '', '', '', '', 'High', '', '', '', '', '', '', '', ''],
'Testing': [NaN, 'Pos', NaN, 'Neg', NaN, NaN, NaN, NaN, 'Pos', NaN,
NaN, NaN, 'Negative', NaN, NaN, NaN, 'Positive', NaN],
'CloseContact': [NaN, NaN, NaN, NaN, 'False', NaN, NaN, 'False', 'True',
NaN, NaN, 'False', NaN, 'True', 'True', 'False', NaN, NaN]}
df1 = pd.DataFrame(data)
df = df1.groupby(['ID', 'Week'])['CloseContact'].apply(lambda x: x[x.notnull()].values[0:2]).reset_index()
df[['CC1','CC2']] = pd.DataFrame(df.CloseContact.tolist(), index= df.index)
df.drop(columns=['CloseContact'], inplace=True)
print(df)
Original DF:
ID Week Risk Testing CloseContact
0 A Week1 High NaN NaN
1 A Week1 Pos NaN
2 A Week1 NaN NaN
3 A Week1 Neg NaN
4 A Week2 NaN False
5 A Week2 NaN NaN
6 A Week2 NaN NaN
7 A Week2 NaN False
8 A Week3 Pos True
9 C Week1 High NaN NaN
10 C Week1 NaN NaN
11 C Week1 NaN False
12 C Week1 Negative NaN
13 C Week2 NaN True
14 C Week2 NaN True
15 C Week2 NaN False
16 C Week2 Positive NaN
17 C Week3 NaN NaN
Final Output:
ID Week CC1 CC2
0 A Week1 None None
1 A Week2 False False
2 A Week3 True None
3 C Week1 False None
4 C Week2 True True
5 C Week3 None None
CodePudding user response:
Like your previous question:
mi = pd.MultiIndex.from_product([df1['ID'].unique(), df1['Week'].unique()],
names=['ID', 'Week'])
out = df1.loc[df1['CloseContact'].notna()] \
.groupby(['ID', 'Week'])['CloseContact'] \
.apply(lambda x: x.head(2).tolist()) \
.apply(pd.Series).rename(columns={0: 'CC1', 1: 'CC2'}) \
.reindex(mi).reset_index()
Output:
>>> out
ID Week CC1 CC2
0 A Week1 True NaN
1 A Week2 False False
2 A Week3 True NaN
3 C Week1 False NaN
4 C Week2 True True
5 C Week3 NaN NaN