How Can I convert this DF from pandas
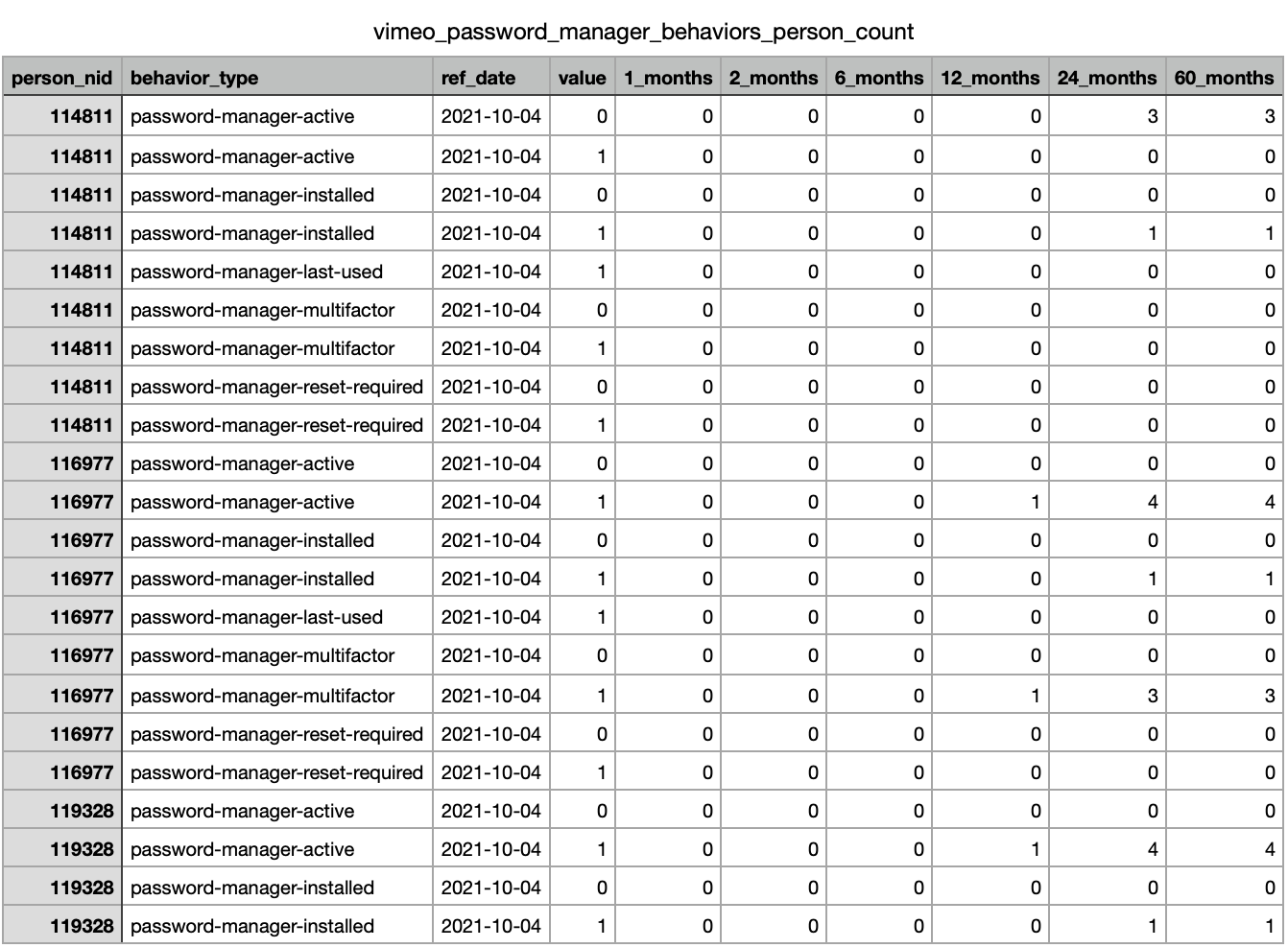
Into this dictionary:
{"114811":{
"password-manager-active":[
{
"ref_date":"2021-10-04",
"value":"0",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"3",
"60_months":"3"
},
{
"ref_date":"2021-10-04",
"value":"1",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
}
],
"password-manager-installed":[
{
"ref_date":"2021-10-04",
"value":"0",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
},
{
"ref_date":"2021-10-04",
"value":"1",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"1",
"60_months":"1"
}
],
"password-manager-last-used":[
{
"ref_date":"2021-10-04",
"value":"1",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
}
],
"password-manager-multifactor":[
{
"ref_date":"2021-10-04",
"value":"0",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
},
{
"ref_date":"2021-10-04",
"value":"1",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
}
],
"password-manager-reset-required":[
{
"ref_date":"2021-10-04",
"value":"0",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
},
{
"ref_date":"2021-10-04",
"value":"1",
"1_months":"0",
"2_months":"0",
"6_months":"0",
"12_months":"0",
"24_months":"0",
"60_months":"0"
}
]
}}
I mean, I need to group by person_nid and behavior_type and then create a list of dicts for the records to be grouped where person_nid is a key with another dictionary inside. In the nested dictionary, the keys are the behavior_type and then the value for every behavior_type is a list of dicts describing each record.
CodePudding user response:
In order to obtain what you are asking, you can filter your DataFrame for each unique user id, and on the filtered Dataframe obtain every row for each behavior_type. You can achieve this with the following code:
import pandas as pd
# read your dataframe inside the df variable
final_dict = dict()
not_nested= ["person_nid", "behaviour_type"]
final_cols= list()
# obtain the inner columns
for col in df.columns:
if col not in not_nested:
final_cols.append(col)
# iterate over all the person_nid
for nid in df["person_nid"].unique():
# dataframe containing only the rows with the current person_nid
nid_df = df[df["person_nid"]==nid]
# create nested dict for current person_nid
final_dict[nid] = dict()
# get all the behaviour_type for the current nid
for btype in nid_df["behaviour_type"].unique():
# create list of dictionaries for the current behaviour_type
final_dict[nid][btype]=list()
# dataframe with the rows for the inner dictionaries
b_df = nid_df[nid_df["behaviour_type"]==btype][final_cols]
# create all the dictionaries inside the list
for index, row in b_df.iterrows():
new_dict = dict()
for col in b_df.columns:
new_dict[col]=row[col]
final_dict[nid][btype].append(new_dict)
If you don't want to create the final dictionaries, you could store a list of the rows returned by b_df.iterrows() since they can be
accessed in the same way of a dictionary with the instruction rows[colname].
If you want to avoid iterations, you can use groupby and apply like in the following code to produce the same result:
not_nested= ["person_nid", "behaviour_type"]
final_cols= list()
for col in df.columns:
if col not in not_nested:
final_cols.append(col)
def external_apply(df):
df= df.groupby("behaviour_type").apply(inner_apply)
return df.to_dict()
def inner_apply(df):
return df[final_cols].to_dict(orient="records")
final_dict =df.groupby("person_nid").apply(external_apply).to_dict()
CodePudding user response:
Something like multiple groups then using to_dict('records') could work.
result = {}
for g,g_hold in df.groupby('person_nid'):
for g2,g2_hold in g_hold[[h for h in g_hold if h != 'person_nid']].groupby('behaviour_type'):
if g in result:
result[g][g2] = g2_hold[[h for h in g2_hold if h != 'behaviour_type']].to_dict('records')
else:
result[g] = {g2:g2_hold[[h for h in g2_hold if h != 'type']].to_dict('records')}