Here I have a simplified dataframe (The real one is in the same format but just amplified)
import pandas as pd
import numpy as np
row = (1, 2)
columns = ["x", "y", "x", "y", "x", "y", "x", "y"]
data = ([10, 2, 8, 1.5, 9, 2, 11, 1.6], [8, 3, 7.5, 2.2, 9, 2, 8.6, 2.3])
df = pd.DataFrame(data, index = row, columns = columns)
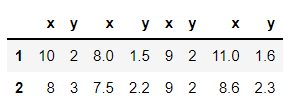
I want to calculate the variance of x, y for both of 1, 2, and the ideal format is

Any hint or help is appreciated
CodePudding user response:
Try this -
- Unstack to get the x, y columns as indexes
- groupby over both the levels [x,y] and [1,2] and calculate variance.
- Unstack and transpose to get [x,y] as columns.
df.unstack().groupby(level=[0,1]).var().unstack().T
x y
1 1.666667 0.069167
2 0.435833 0.189167