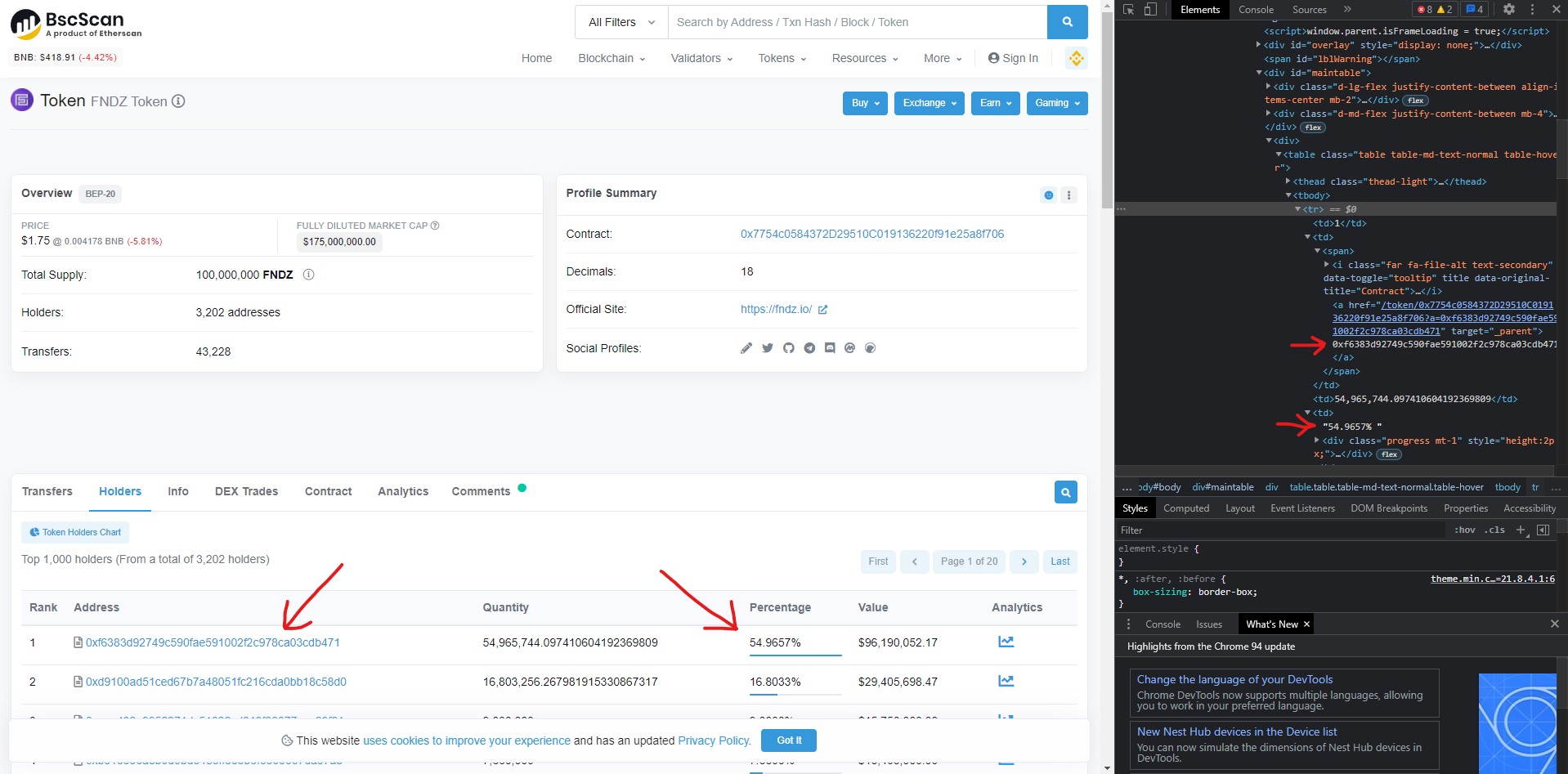
I have combed this site and have tried several approaches to no avail. I'm trying to scrape the top holder percentage and wallet address of a token from bscscan.com (see attached pic). Here are my attempts. Bscscan API would have put me out of my misery if the endpoint with this info wasn't a premium service. Also if you know a less painful way to obtain this info please don't hold back. Pls advise on any of the methods below, thanks in advance.
import requests
from bs4 import BeautifulSoup
from lxml import etree
token = "0x7754c0584372D29510C019136220f91e25a8f706"
url = f"https://bscscan.com/token/{token}#balances"
#First attempt
webpage = requests.get(url)
soup = BeautifulSoup(webpage.content, "html.parser")
d = etree.HTML(str(soup))
print(d.xpath('//*[@id="maintable"]/div[3]/table/tbody/tr[1]/td[4]/text()'))
print(d.xpath('//*[@id="maintable"]/div[3]/table/tbody/tr[1]/td[2]/span/a'))
#Second attempt
from lxml import etree
holding = etree.parse(url, etree.HTMLParser())
holding.xpath('//[@id="maintable"]/div[3]/table/tbody/tr[1]/td[4]/text()')
print(holding)
#Third attempt
for tr in soup.find_all('<td>1</td>'):
tds = tr.find_all('_parent')
tds.get_text()
print(tds)
#Fourth attempt
from parsel import Selector
import requests
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
response = requests.get("https://bscscan.com/token/generic-tokenholders2?m=normal&a=0x7754c0584372D29510C019136220f91e25a8f706&s=100000000000000000000000000&sid=066c697ef6a537ed95ccec0084a464ec&p=1", headers)
sel = Selector(response.text)
address = sel.css("tr>td>a::attr(_parent)").extract()
percentage = sel.css("tr>td[3]").extract()
print(address)
print( percentage)
CodePudding user response:
Your 4th attempt is very close! What you should do instead is iterate through each row and extract data based on column numbers:
for row in sel.css('tr'):
# percentage is on 5th column
perc = row.xpath('td[4]/text()').get()
if not perc: # skip rows with no percentage info
continue
# addres is on 2nd collumn under <a> node
# we can also use `re()` method to only take the token part of the url
addr = row.xpath('td[1]//a/@href').re('/token/([^#?] )')[0]
print(addr, perc)
which results in:
0x7754c0584372D29510C019136220f91e25a8f706 54.9648%
0x7754c0584372D29510C019136220f91e25a8f706 16.8033%
0x7754c0584372D29510C019136220f91e25a8f706 9.0000%
0x7754c0584372D29510C019136220f91e25a8f706 7.6600%
0x7754c0584372D29510C019136220f91e25a8f706 1.2000%
...
Also noticed there's a slight typo in your request line:
response = requests.get("...", headers)
^^^^^^^
# this part should be keyword argument
response = requests.get("...", headers=headers)