I am using argrelextrema from scipy to identify peaks in my data. The data looks something like this:
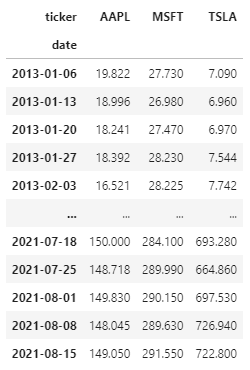
Now argrelextrema finds me the peaks in the data and outputs two arrays (row and column indices).
argrelextrema(df.values, np.greater, axis=0,order=1)

Now, out of my original data, I would like to create a boolean array where the peaks are identified as True, and the rest else False.
Something like this (only illustration).
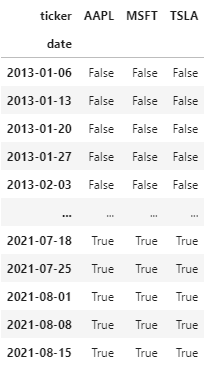
Usually I would achieve something like the above with an np.where, but since I now have row and column indices, I didn't find a way how to use that with an np.where clause.
Also, I would like to have a vectorized solution, if possible.
CodePudding user response:
As pointed out argrelextrema returns the indices of the relative extrema values.
Use those indices to index directly into a boolean array of the same shape as your original DataFrame:
import numpy as np
import pandas as pd
from scipy.signal import argrelextrema
# for reproducibility
np.random.seed(42)
# create toy DataFrame
df = pd.DataFrame(data=np.random.random((100, 3)) * 20, columns=["AAPL", "MSFT", "TSLA"])
# extract rows and cols indices using extrema
rows, cols = argrelextrema(df.values, np.greater, axis=0,order=1)
# create boolean numpy array
values = np.zeros_like(df.values, dtype=bool)
# set the values of the extrema to True
values[rows, cols] = True
# convert to DataFrame
result = pd.DataFrame(data=values, columns=df.columns)
print(result)
Output
AAPL MSFT TSLA
0 False False False
1 False False True
2 False False False
3 False True True
4 False False False
.. ... ... ...
95 False False False
96 True False True
97 False False False
98 True True True
99 False False False
[100 rows x 3 columns]
The important part of the code above is this:
# create boolean numpy array
values = np.zeros_like(df.values, dtype=bool)
# set the values of the extrema to True
values[rows, cols] = True
As an alternative you could directly built the values array, from a sparse.csr_matrix:
from scipy.sparse import csr_matrix
values = csr_matrix((np.ones(rows.shape), (rows, cols)), shape=df.shape, dtype=bool).toarray()