I'm creating an additional column "Total_Count" to store the cumulative count record by Site and Count_Record column information. My coding is almost done for total cumulative count. However, the Total_Count column is shift for a specific Card as below. Could someone help with code modification, thank you!
Expected Output:
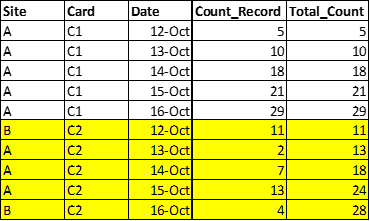
Current Output:
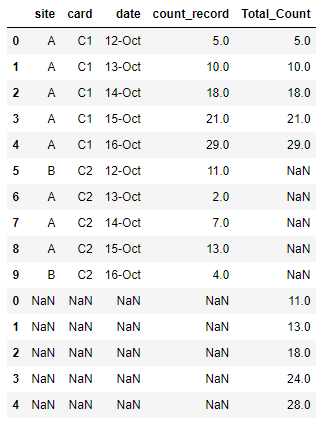
My Code:
import pandas as pd
df1 = pd.DataFrame(columns=['site', 'card', 'date', 'count_record'],
data=[['A', 'C1', '12-Oct', 5],
['A', 'C1', '13-Oct', 10],
['A', 'C1', '14-Oct', 18],
['A', 'C1', '15-Oct', 21],
['A', 'C1', '16-Oct', 29],
['B', 'C2', '12-Oct', 11],
['A', 'C2', '13-Oct', 2],
['A', 'C2', '14-Oct', 7],
['A', 'C2', '15-Oct', 13],
['B', 'C2', '16-Oct', 4]])
df_append_temp=[]
total = 0
preCard = ''
preSite = ''
preCount = 0
for pc in df1['card'].unique():
df2 = df1[df1['card'] == pc].sort_values(['date'])
total = 0
for i in range(0, len(df2)):
site = df2.iloc[i]['site']
count = df2.iloc[i]['count_record']
if site == preSite:
total = (count - preCount)
else:
total = count
preCount = count
preSite = site
df2.loc[i, 'Total_Count'] = total #something wrong using loc here
df_append_temp.append(df2)
df3 = pd.DataFrame(pd.concat(df_append_temp), columns=df2.columns)
df3
CodePudding user response:
I am not sure if there is a vectorized way to do this cumulative summation. However, we can use groupby to create our df2 which allows us to apply a function to each grouped DataFrame to create the new column. This should offer similar performance as the current implementation but produce correctly aligned Series:
def calc_total_count(df2: pd.DataFrame) -> pd.Series:
total = 0
pre_count = 0
pre_site = ''
lst = []
for c, s in zip(df2['count_record'], df2['site']):
if s == pre_site:
total = (c - pre_count)
else:
total = c
pre_count = c
pre_site = s
lst.append(total)
return pd.Series(lst, index=df2.index, name='Total_Count')
df3 = pd.concat([
df1,
df1.sort_values('date').groupby('card').apply(calc_total_count).droplevel(0)
], axis=1)
df3:
site card date count_record Total_Count
0 A C1 12-Oct 5 5
1 A C1 13-Oct 10 10
2 A C1 14-Oct 18 18
3 A C1 15-Oct 21 21
4 A C1 16-Oct 29 29
5 B C2 12-Oct 11 11
6 A C2 13-Oct 2 13
7 A C2 14-Oct 7 18
8 A C2 15-Oct 13 24
9 B C2 16-Oct 4 28
Setup and imports:
import pandas as pd
df1 = pd.DataFrame(columns=['site', 'card', 'date', 'count_record'],
data=[['A', 'C1', '12-Oct', 5],
['A', 'C1', '13-Oct', 10],
['A', 'C1', '14-Oct', 18],
['A', 'C1', '15-Oct', 21],
['A', 'C1', '16-Oct', 29],
['B', 'C2', '12-Oct', 11],
['A', 'C2', '13-Oct', 2],
['A', 'C2', '14-Oct', 7],
['A', 'C2', '15-Oct', 13],
['B', 'C2', '16-Oct', 4]])