From the RFC7540:
While HTTP/1.x used the message start-line (see [RFC7230], Section 3.1) to convey the target URI, the method of the request, and the status code for the response, HTTP/2 uses special pseudo-header fields beginning with ':' character (ASCII 0x3a) for this purpose.
So why HTTP/2 uses Pseudo-Header Fields? Is there anything wrong with the message start-line in HTTP/1.x?
CodePudding user response:
Lending an image from 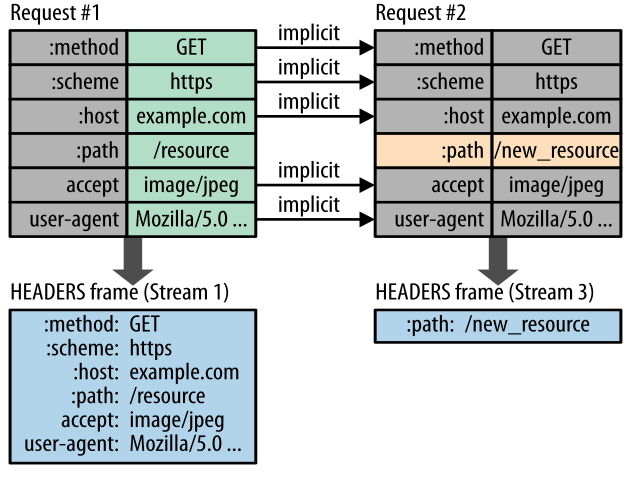
In this picture you can see that on the first request the first two header lines which are usually like:
GET /resoure HTTP/1.1
Host: https://example.com
...
are now split up into a headers frame like this
:method: GET
:scheme: https
:host: example.com
:path: /resource
...
while the remaining headers are more or less the same, except for being all lower-case characters.
HTTP/2 tries to minimize the payload size as much as possible. It will also compress headers and strip headers that are equal to the headers sent in the previous request, as can be seen in the right part of the linked image.
In HTTP/1.1 a consecutive request looked like the first initial request just targeting a different resource:
GET /otherResource HTTP/1.1
Host: https://example.org
...
while in HTTP/2 a consecutive request to the same server just requires
:path: /otherResource
as all of the other headers are already available and can be restored from the previously cached and indexed headers.
This is therefore an optimization to reduce the payload on consecutive requests further.
CodePudding user response:
HTTP/2 is new protocol, and with binary encoding.
There is no status line in HTTP/2, just like there are no 'lines' for individual headers. An entirely new way had to be invented to encode every part of a HTTP request.
Headers are effectively a key->value structure. Instead of inventing a different encoding for the things appearing on the first line of a HTTP/1.1 requests, it makes the protocol simpler if the same approach to encoding is used for this stuff.
After all, things like the 'path' and 'http method' are already in the header, why not take the same approach for encoding them as regular headers. The : in front ensures that there's no clashes with existing HTTP/1.1 headers, because the name of a header can never contain :.
So the tl;dr is: by encoding the information from the first line of HTTP requests and responses as special HTTP headers, the protocol could be simpler.