Assuming that I have a df like this:
import pandas as pd
data = {"name": ["nameA", "nameB", "nameC", "nameD", "nameA", "nameB", "nameC", "nameD", "nameE", "nameA", "nameC", "nameD"],
"id": [100, 200, 300, 400, 100, 200, 300, 400, 500, 100, 300, 400],
"value": ["v1", "v2", "v3", "v4", "v1", "v2", "v105", "v107", "v5", "v1", "v3615", "v4"]}
df = pd.DataFrame(data)
df
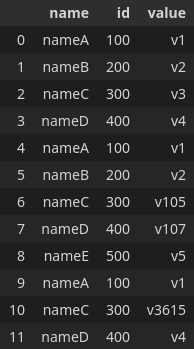
I want to group the rows if they are duplicated values in name and id and different values in the value column. The idea is that if name and id are the same, they must have same value which is not always true and I want to extract the offending indexes. For example, I want to have an output like this:
(2, 6, 10), (3, 7, 11)
where the name and ID are the same but the value on one of the duplicated rows is different, like ("v4", "v107", "v4").
I can group the values with duplicated but I am getting a list of all duplicated values
df[df.duplicated(["name", "id"])]
This results in
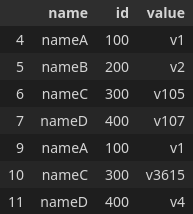
The values under index 4 and 9 are the same so I don't care about this one.
I guess this is really simple but I am just stuck at this for at least an hour and can't figure it out.
CodePudding user response:
Try with groupby and filter
out = df.groupby(["name", "id"]).filter(lambda x : x['value'].nunique() == len(x))
CodePudding user response:
Use groupby() agg() nunique() to extract the lists of indexes where the group has unique values >= 2, as follows:
idx_lst_all = df.groupby(['name', 'id'])['value'].agg(lambda x : x.index[x.nunique() >=2]).values
# convert non-empty lists to tuples
idx_lst_selected = [tuple(x[0]) for x in idx_lst_all if x.size > 0]
Result:
print(idx_lst_selected)
[(2, 6, 10), (3, 7, 11)]