My DataFrame has several columns representing specific measurements for the different specimens, and the numbers of rows (measurement points) for each sample are not the same. e.g.
df=
p1 v1 dv1 p9 v9 dv9 p21 v21 dv21 p26 v26 r26 dv26
0 0.977966 0.000544 NaN 0.928902 0.000000 NaN 1.140129 0.000000 NaN 1.002083 0.000000 106.478206 NaN
1 1.022041 0.001087 0.000543 0.953850 0.000000 0.000000 1.175056 0.000153 0.000153 1.079422 0.000208 98.849199 0.000208
2 1.050316 0.001268 0.000181 0.984619 0.000000 0.000000 1.204163 0.000153 0.000000 1.140961 0.000208 93.517657 0.000000
3 1.082748 0.001268 0.000000 1.010399 0.000261 0.000261 1.224953 0.000153 0.000000 1.249901 0.000208 85.366761 0.000000
4 1.109360 0.001268 0.000000 1.031189 0.000261 0.000000 1.247406 0.000153 0.000000 1.314766 0.000208 81.155126 0.000000
5 1.127655 0.001268 0.000000 1.056969 0.000261 0.000000 1.277344 0.000306 0.000153 1.459465 0.000417 73.108982 0.000209
6 1.160087 0.001268 0.000000 1.086075 0.000261 0.000000 1.302292 0.000459 0.000153 1.629112 0.000624 65.495804 0.000208
7 1.209152 0.001268 0.000000 1.117676 0.000392 0.000131 1.328072 0.000459 0.000000 1.658218 0.000624 64.346184 0.000000
8 1.259048 0.001268 0.000000 1.151772 0.000392 0.000000 1.370483 0.000612 0.000153 1.748863 0.000624 61.011068 0.000000
9 1.283165 0.001268 0.000000 1.180878 0.000392 0.000000 1.399590 0.000612 0.000000 1.920174 0.000624 55.567881 0.000000
10 1.362167 0.001268 0.000000 1.227448 0.000392 0.000000 1.426201 0.000612 0.000000 2.064041 0.000833 51.694710 0.000209
11 1.446991 0.001449 0.000181 1.278175 0.000392 0.000000 1.475266 0.000612 0.000000 2.252815 0.000833 47.362966 0.000000
12 1.473602 0.001630 0.000181 1.297302 0.000522 0.000130 1.541794 0.000765 0.000153 2.432442 0.000833 43.865383 0.000000
13 1.667366 0.001630 0.000000 1.316429 0.000522 0.000000 1.639923 0.000765 0.000000 2.614563 0.000833 40.809879 0.000000
14 1.837845 0.001630 0.000000 1.344704 0.000652 0.000130 1.712273 0.000919 0.000153 2.812485 0.000833 37.937980 0.000000
15 2.042419 0.001630 0.000000 1.412063 0.000783 0.000131 1.861130 0.000919 0.000000 2.984627 0.000833 35.749861 0.000000
16 2.222878 0.001630 0.000000 1.476929 0.000783 0.000000 2.029114 0.001531 0.000612 3.014565 0.001041 35.394825 0.000208
17 2.256142 0.001630 0.000000 1.497719 0.000913 0.000130 2.052398 0.001531 0.000000 3.169243 0.001041 33.667346 0.000000
18 2.422463 0.001630 0.000000 1.672356 0.001305 0.000392 2.163834 0.001531 0.000000 3.354691 0.001041 31.806208 0.000000
19 2.602089 0.001630 0.000000 1.833687 0.001566 0.000261 2.343460 0.001837 0.000306 3.386292 0.001041 31.509391 0.000000
20 2.634522 0.001630 0.000000 1.857803 0.001696 0.000130 2.496475 0.001837 0.000000 3.565086 0.001041 29.929152 0.000000
21 2.821633 0.001812 0.000181 1.880257 0.001696 0.000000 2.683586 0.001990 0.000153 3.772987 0.001041 28.279981 0.000000
I want to create a new DataFrame containing rows values corresponding to dv1>0, dv9>0.etc. Here, I want to filter all the corresponding columns of the same sample (p1 v1 etc.) when the condition satisfy (dv>0) and shows the values of the corresponding row, e.g. when dv1>0, it should show the values of the row of p1, v1 and dv1 similarly when dv9>0 it should sow corresponding rows of p9, v9 and dv9.
when I apply df_new=df[df.dv1>0] #filter value >0, it is applied on all the columns
What can I do to achieve this? Any help in this regard is highly appreciated.
desire output should be like this
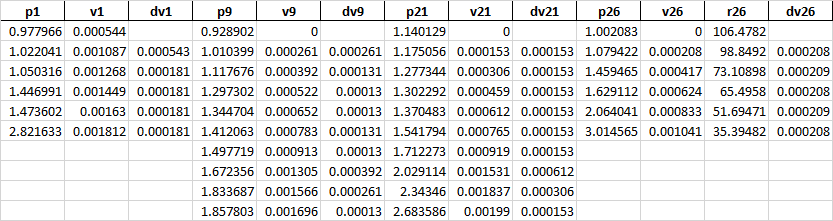
CodePudding user response:
There's an option with wide_to_long, if you know all of the prefixes:
out = (pd.wide_to_long(df.reset_index(), # temporary make index
stubnames=['p','v','dv','r'], # the prefixes
i='index', j='enum')
.query('dv>0') # filter here
.reset_index('index', drop=True) # remove the old index
)
out = (out.set_index(out.groupby('enum').cumcount(), append=True) # enumerate within each suffix 1, 9, etc
.unstack('enum').sort_index(level=[1,0], axis=1) # unstack to get long
.dropna(how='all', axis=1) # drop empty columns
)
out.columns = [f'{x}{y}' for x,y in out.columns] # rename columns
CodePudding user response:
You can do this:
df_new = df[df['dv1']>0][['p1', 'v1', 'dv1']]