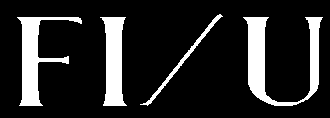I'm attempting to prepare images for OCR by Tesseract. However certain character sequences touch (due to the serifs on the font glyphs), and this confuses it.
For example I/U:

I notice a bright outline to each character. If that could be replaced with a dark colour the letters would gain some breathing space.
img_grey[img_grey > 100] = 0
... But I can't quite make it work.
Is anyone aware of a better technique?
CodePudding user response:
You could try to erode the image, in opencv there is an operation called eroding, it basicly shrinks the character thickness in this case. This should allow some space between the characters but be careful not to over do it or else tesseract might not be able to recognize the character. To can get the right amount of errosion by trial and error.
Refer to this