I have a raw data exported and transformed a bit from salesforce below;
df = pd.DataFrame(columns=['contact_start','name', 'aht'],
data=[['2021-09-27 09:58:00','Venus','180'],
['2021-09-27 10:00:00','Venus','240'],
['2021-09-27 11:05:00','Venus','60'],
['2021-09-27 10:55:00','Mars','30'],
['2021-09-27 10:56:00','Mars','30']])
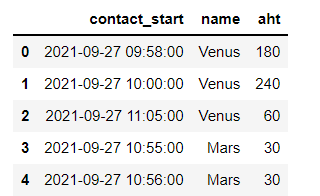
using these codes below
df["contact_start"] = pd.to_datetime(df["contact_start"], format = "%Y-%m-%d %H:%M:%S",errors='coerce')
df["date"] = df["contact_start"].dt.strftime('%Y-%m-%d')
df['aht']=pd.to_datetime(df["aht"], unit='s').dt.strftime("%H:%M:%S")
df['contact_finish'] = pd.to_timedelta(df['aht']) pd.to_datetime(df['contact_start'])
df['contact_finish'] = df['contact_finish'].astype('datetime64[s]')
I transform this into :
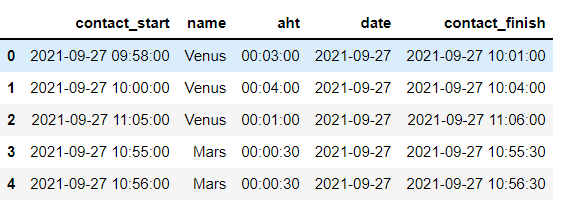
but my final goal is to deal with overlapping and I ran out of ideas how to make it happen.
the outcome should be like this in below:
df = pd.DataFrame(columns=['date','name', 'total_duration_sec'],
data=[['2021-09-27','Venus','420'],
['2021-09-27','Mars','60']])
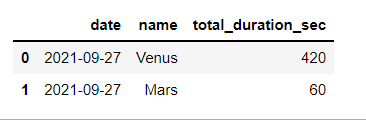
I guess it looks simple but in fact it is really not. I would appreciate any help.
CodePudding user response:
I think you could create a time difference in seconds between successive contact_start per name
upper_seconds = (
df.sort_values(['name','contact_start'])
.groupby('name')['contact_start'].diff(-1)
.dt.total_seconds().abs())
print(upper_seconds.sort_index())
# 0 120.0
# 1 3900.0
# 2 NaN
# 3 60.0
# 4 NaN
# Name: contact_start, dtype: float64
Now you can use this as a upper clip on aht then groupby name and date and sum.
res = (
df['aht'].astype(int)
.clip(upper=upper_seconds)
.groupby([df['name'], df['date']]).sum()
.reset_index(name='total_duration_sec')
)
print(res)
name date total_duration_sec
0 Mars 2021-09-27 60
1 Venus 2021-09-27 420
Note that I used first two lines you already wrote to have the good type.
df["contact_start"] = pd.to_datetime(df["contact_start"],
format = "%Y-%m-%d %H:%M:%S",errors='coerce')
df["date"] = df["contact_start"].dt.strftime('%Y-%m-%d')
CodePudding user response:
You can make your existing code work by adding these lines to your code:
overlapped = pd.Series(df.groupby(['name']).apply(lambda x: (x['contact_finish'] - x['contact_start'].shift(-1)).dt.total_seconds().shift()).droplevel(0), name='overlapped')
overlapped = overlapped.mask(overlapped<0, 0).fillna(0)
df['date'] = df['contact_start'].dt.date
df = df.groupby(['date', 'name']).apply(lambda x: (((x['contact_finish'] - x['contact_start']).dt.seconds) - overlapped).sum()).reset_index(name='total_duration_sec')
OUTPUT:
date name total_duration_sec
0 2021-09-27 Mars 60.0
1 2021-09-27 Venus 420.0