I have a table with duplicate records, where I've already created a script to summarize the duplicate records with the original ones, but I'm not able to delete the duplicate records.
I'm trying this way:
DELETE FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
WHERE COD_PLANO_PAGAMENTO IN (SELECT MAX(COD_PLANO_PAGAMENTO) COD_PLANO_PAGAMENTO
FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
GROUP BY COD_PLANO_PAGAMENTO)
The idea was to take the last record of each COD_PLANO_PAGAMENTO and delete it, but this way all the records are being deleted, what am I doing wrong?
The table is structured as follows:
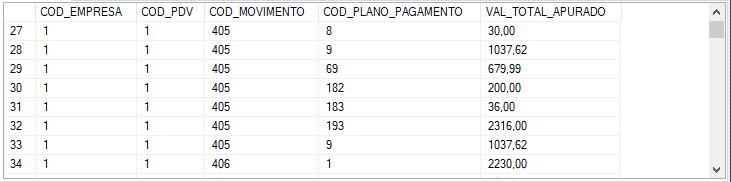
I need to delete, for example, the second record of COD_MOVIMENTO = 405 with COD_PLANO_PAGAMENTO = 9, there should only be one record of COD_PLANO_PAGAMENTO different in each COD_MOVIMENTO
CodePudding user response:
You can use an updatable CTE with row-numbering to calculate which rows to delete.
You may need to adjust the partitioning and ordering clauses, it's not clear exactly what you need.
WITH cte AS (
SELECT *,
rn = ROW_NUMBER() OVER (PARTITION BY COD_MOVIMENTO, COD_PLANO_PAGAMENTO ORDER BY (SELECT 1)
FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO mp
)
DELETE FROM cte
WHERE rn > 1;
CodePudding user response:
Your delete statement will take the max() but even if you have only one record, it'll return a value.
Also note that your group by should be on COD_MOVIMENTO.
As a fix, make sure there are at least two items:
DELETE FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
WHERE COD_PLANO_PAGAMENTO IN
(SELECT MAX(COD_PLANO_PAGAMENTO)COD_PLANO_PAGAMENTO
FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
WHERE cod_plano_pagamento in
(select cod_plano_pagamento
from TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
group by COD_PLANO_PAGAMENTO
having count(*) > 1)
GROUP BY COD_MOVIMENTO )
CodePudding user response:
In your comment you want remove duplicate rows with same COD_MOVIMENTO, COD_PLANO_PAGAMENTO and VAL_TOTAL_APURADO, try this:
delete f1 from
(
SELECT *, ROW_NUMBER() OVER (PARTITION BY COD_MOVIMENTO, COD_PLANO_PAGAMENTO, VAL_TOTAL_APURADO ORDER BY COD_MOVIMENTO) rang
FROM TB_MOVIMENTO_PDV_DETALHE_PLANO_PAGAMENTO
) f1
where f1.rang>1