I am doing a migration job from pyspark query into snowflake query and wondering which option is better between below A, B options.
To avoid unnecessary query, I would like to go B option if there are not that significant performance difference.
In B option, does snowflake query engine automatically optimize and internally behaves like the A option?
A option
With A1 AS (select * from a1 where date='2021-10-20'),
A2 AS (select * from a2 where date='2021-10-20'),
A3 AS (select * from a3 where date='2021-10-20'),
A4 AS (select * from a4 where date='2021-10-20'),
A5 AS (select * from a5 where date='2021-10-20')
SELECT *
FROM final_merged_table
and B option
With A1 AS (select * from a1),
A2 AS (select * from a2),
A3 AS (select * from a3),
A4 AS (select * from a4),
A5 AS (select * from a5)
SELECT *
FROM final_merged_table
WHERE date = '2021-10-20'
CodePudding user response:
We can test this. First, let's construct a table with a week of dates and several million rows:
create or replace table one_week2
as
select '2020-04-01'::date (7*seq8()/100000000)::int day, random() data, random() data2, random() data3
from table(generator(rowcount => 100000000))
Now we can write both queries to go over this table:
Option 1:
With A1 AS (select * from one_week2 where day='2020-04-05'),
A2 AS (select * from one_week2 where day='2020-04-05'),
A3 AS (select * from one_week2 where day='2020-04-05'),
A4 AS (select * from one_week2 where day='2020-04-05'),
A5 AS (select * from one_week2 where day='2020-04-05'),
final_merged_table as (
select * from a1
union all select * from a2
union all select * from a3
union all select * from a4
union all select * from a5)
SELECT count(*)
FROM final_merged_table
Option 2:
With A1 AS (select * from one_week2),
A2 AS (select * from one_week2),
A3 AS (select * from one_week2),
A4 AS (select * from one_week2),
A5 AS (select * from one_week2),
final_merged_table as (
select * from a1
union all select * from a2
union all select * from a3
union all select * from a4
union all select * from a5)
SELECT count(*)
FROM final_merged_table
where day='2020-04-05'
;
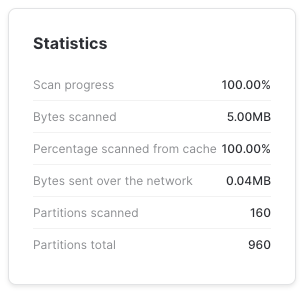
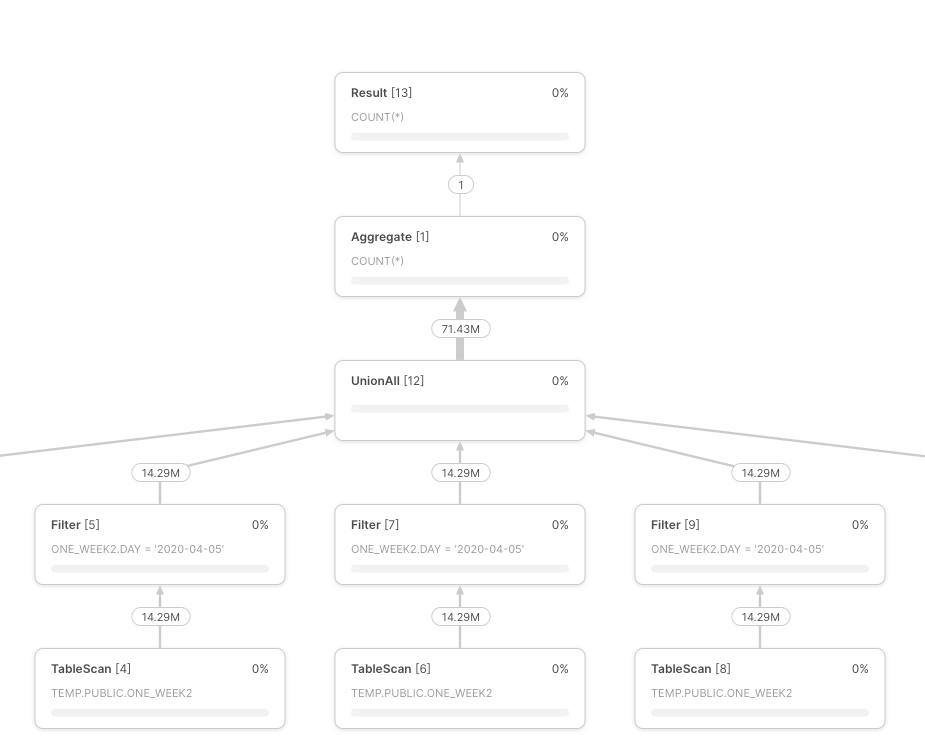
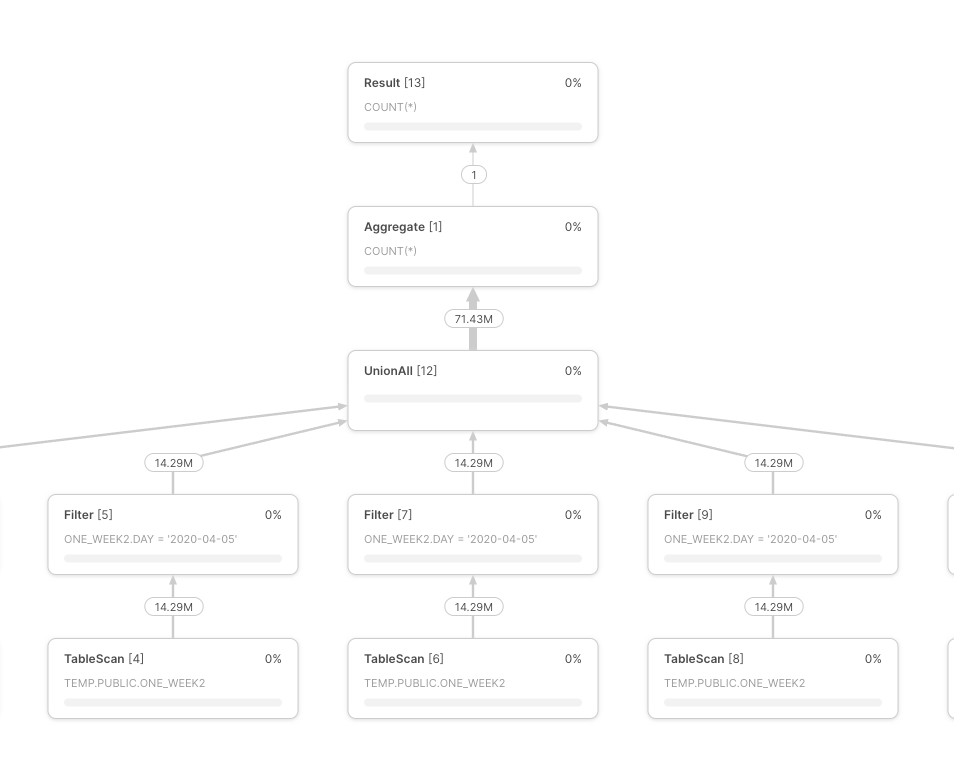
When we run these queries, the profile for both looks identical - as the filter has been pushed down:
Option 1 profile
Option 2 profile
In summary
You can trust the Snowflake optimizer.
Trust is important, but also verify: Sometimes the optimizer can get confused by convoluted CTEs. Sometimes the Snowflake engs optimize the optimizer, and what doesn't work today, can work better tomorrow.