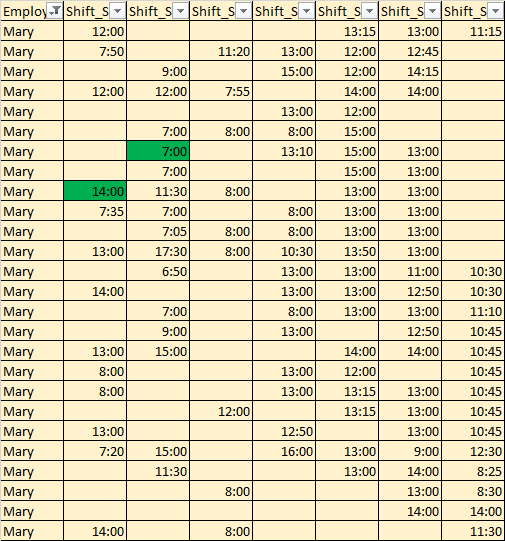
I have a table with weekly data of the start time of employees, How to write the most efficient SQL to find the most common start date for each day in the week?
I expect to get some thing like

CodePudding user response:
Consider below approach
select * from (
select employee, shift, array_agg(start_time order by freq desc limit 1)[offset(0)] start_time
from (
select employee, shift, start_time, count(1) freq
from mytable
unpivot (start_time for shift in (Shift_S1, Shift_S2, Shift_S3, Shift_S4, Shift_S5, Shift_S6, Shift_S7))
group by employee, shift, start_time
)
group by employee, shift
)
pivot (min(start_time) for shift in ('Shift_S1', 'Shift_S2', 'Shift_S3', 'Shift_S4', 'Shift_S5', 'Shift_S6', 'Shift_S7'))
if applied to sample data in your question - output is

CodePudding user response:
Try 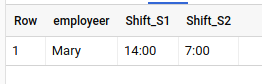
Update for ignoring NULLs:
with mytable as (
select 'Mary' as employeer, '14:00' as Shift_S1, '9:00' as Shift_S2 union all
select 'Mary', '12:00', '7:00' union all
select 'Mary', '14:00', '7:00' union all
select 'Mary', NULL, NULL union all
select 'Mary', NULL, NULL union all
select 'Mary', NULL, '8:00'
)
select
employeer,
IFNULL(APPROX_TOP_COUNT(Shift_S1, 2)[OFFSET(0)].value, APPROX_TOP_COUNT(Shift_S1, 2)[OFFSET(1)].value) as Shift_S1,
IFNULL(APPROX_TOP_COUNT(Shift_S2, 2)[OFFSET(0)].value, APPROX_TOP_COUNT(Shift_S2, 2)[OFFSET(1)].value) as Shift_S2
from mytable
group by employeer