I have a table with the following sample data. The table actually contains more than 10 million rows.
| tableid | Id | type |
|---|---|---|
| 1 | 1 | su1 |
| 2 | 2 | su1 |
| 3 | 2 | su2 |
| 4 | 3 | su3 |
| 5 | 4 | su1 |
I have to get a count of all the ids that only have type su1. If the id has su1 but also another type then it should not be counted. This is the query I came up with.
Select Count(*) From (
Select id
From table t
Where exists (select null from table t1 where t.id = t1.id and t1.type = 'su1')
Group by id
Having Count(*) = 1) a
tableid is the primary key. Id has a non-clustered index on it. Are there any other ways of writing this query?
CodePudding user response:
Given this table and sample data:
CREATE TABLE dbo.[table]
(
tableid int,
Id int,
type char(3),
INDEX IX_table CLUSTERED (Id, type)
);
INSERT dbo.[table](tableid, Id, type) VALUES
(1, 1, 'su1'),
(2, 2, 'su1'),
(3, 2, 'su2'),
(4, 3, 'su3'),
(5, 4, 'su1');
One way would be:
;WITH agg AS
(
SELECT tableid, Id, type,
mint = MIN(Type) OVER (PARTITION BY Id),
maxt = MAX(Type) OVER (PARTITION BY Id)
FROM dbo.[table]
)
SELECT tableid, Id, type
FROM agg
WHERE mint = maxt AND mint = 'su1';
If your clustered index is on Id, type this will allow for a single clustered index scan:
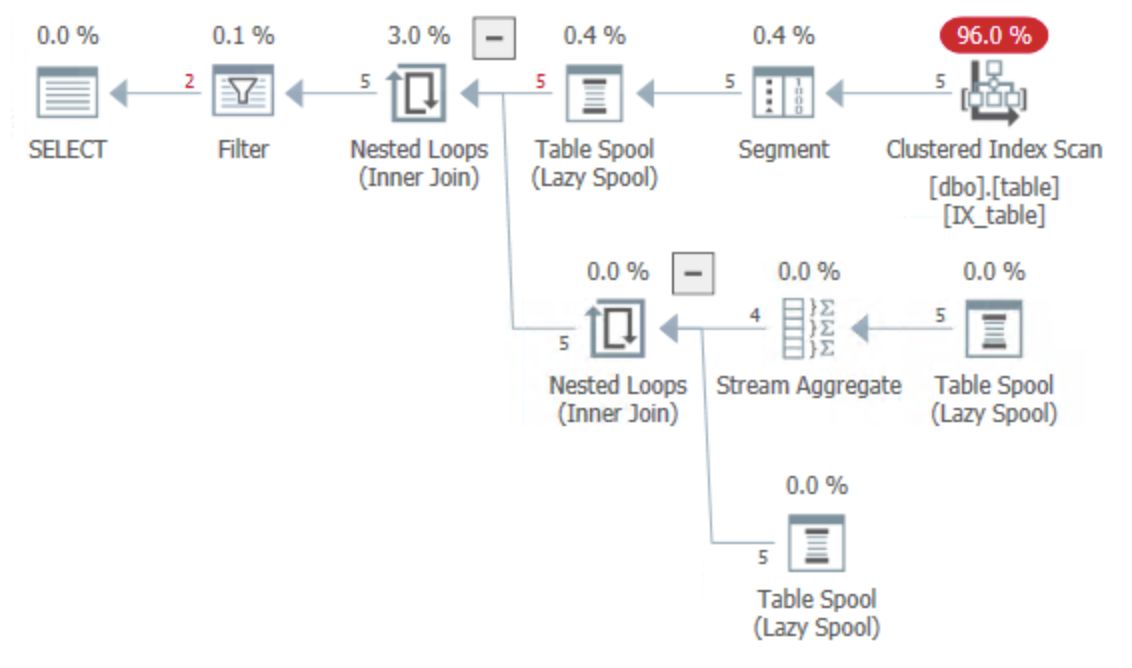
Though it is a little messy with some spools that we might not want. How about David's suggestion (assuming you're on SQL Server 2017 or better):
SELECT tableid = MIN(tableid), Id
FROM dbo.[table]
GROUP BY Id
HAVING STRING_AGG(type, ',') = 'su1';
Oh yeah, that's much better:

- Examples on db<>fiddle
CodePudding user response:
I'm not entirely sure why you have Having Count(*) = 1 as it doesn't seem to be reflected in the requirements.
But this query is much better written as follows
SELECT COUNT(*)
FROM (
SELECT id
FROM [table] t
GROUP BY id
HAVING COUNT(CASE WHEN t1.type <> 'su1' THEN 1 END) = 0
) t;
And for that, you would need the following index
[table] (id) INCLUDE (type)
CodePudding user response:
Maybe I'm missing something but can't you do a COUNT DISTINCT after filtering out everything except the items with type='su1'. In that case we'd just have:
WITH tbl (tableid, id, type) AS (
select * from values (1,1,'su1'), (2,2,'su1'), (3,2,'su2'), (4,3,'su3'), (5,4,'su1')
)
SELECT COUNT(DISTINCT id) FROM tbl
WHERE id NOT IN (SELECT id FROM tbl WHERE type != 'su1')
-- 2
Here is the SQL Fiddle, I removed the COUNT DISTINCT so you can see the individual results and it's easier to check here.