I have DataFrame that looks like:
import pandas as pd
df = pd.DataFrame({'Customer': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B','B','B','B','B','B'],
'Date': ['1/1/2021', '2/1/2021','3/1/2021', '4/1/2021','5/1/2021', '6/1/2021','7/1/2021', '1/1/2021', '2/1/2021','3/1/2021', '4/1/2021','5/1/2021', '6/1/2021','7/1/2021'],
'Amt': [0, 10, 0, 10, 0, 0, 0, 0, 0, 10, 10, 0, 10, 10]})
df
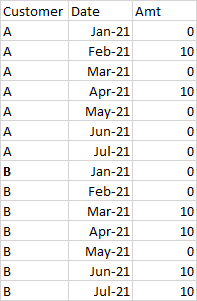
I'm trying to calculate the beginning and end date for each, which I think is pretty straight forward (i.e., first time each customer customer and last time, as defined by amt > 0).
What I need help with is calculating the number of new acquisitions, whether it's their first purchase or they've churned for a period and come back. For example, for Customer A the first is Feb-21 and the second would be Apr-21. Moreover, Customer B would be Mar-21 and then again on Jun-21. Both would have two new
The desired output would be:
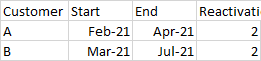
I'm just not sure where to start on this one.
CodePudding user response:
One way using pandas.DataFrame.groupby with shift trick:
df["grp"] = df["Amt"].ne(df["Amt"].shift()).cumsum()
new_df = df[df["Amt"].gt(0)].groupby("Customer").agg(Start=("Date", min),
End=("Date", max),
Reactivation=("grp", "nunique"))
print(new_df)
Output:
Start End Reactivation
Customer
A 2021-02-01 2021-04-01 2
B 2021-03-01 2021-07-01 2
CodePudding user response:
In this answer I'm assuming your date is monthly frequency pandas.Timestamps. If it is something similar like pandas.Period then this solution can be tweaked.
The solution involves grouping on Customer then applying a function to create a pandas.IntervalIndex for each customer, which holds an interval for each month. The following function does this, then filters out any intervals corresponds to zero values for Amt:
def create_intervals(sub_df):
months = pd.PeriodIndex(sub_df["Date"], freq="M")
return pd.IntervalIndex.from_arrays(
months.start_time,
(months 1).start_time
)[sub_df["Amt"]>0]
Use it like so to get a pandas.Series, indexed by customer, whose values are pandas.IntervalIndex
intervals = df.groupby("Customer").apply(create_intervals)
The value of intervals will be
Customer
A IntervalIndex([(2021-02-01, 2021-03-01], (2021...
B IntervalIndex([(2021-03-01, 2021-04-01], (2021...
dtype: object
Last step is to import piso and use the union function to combine adjacent intervals in each IntervalIndex, and then finally calculate the number of intervals remaining
import piso
intervals.apply(piso.union).apply(len)
The result
Customer
A 2
B 2
dtype: int64
Start and end dates can be calculated with
intervals.apply(lambda i: i.left.min())
intervals.apply(lambda i: i.left.max())
respectively. Stitch it together:
(
intervals
.apply(piso.union)
.apply(len)
.rename("Reactivated")
.reset_index()
.assign(Start = intervals.apply(lambda i: i.left.min()))
.assign(End = intervals.apply(lambda i: i.left.max()))
)
CodePudding user response:
First you want to convert your strings into datetime objects using datetime so that we can compare them. Then filter all rows out with amount = 0. Then group you data by customer and aggregate the date column of the grouped data by min, max, and count.
df['Date'] = pd.to_datetime(df['Date'], format='%d/%m/%Y')
df = df[df['Amt'] > 0]
df = df.groupby('Customer').agg({'Date': ['min', 'max', 'count']})
df.columns = df.columns.droplevel(0)
print(df)
# Date
# min max count
#Customer
#A 2021-01-02 2021-01-04 2
#B 2021-01-03 2021-01-07 4
The result is a column hierarchy with two levels. Remove the outer level with:
df.columns = df.columns.droplevel(0)
print(df)
# min max count
#Customer
#A 2021-01-02 2021-01-04 2
#B 2021-01-03 2021-01-07 4
Keep in mind that your customers are now the index of your dataframe. Read more about groupby and agg from the pandas docs.