I am trying to use batch_writer() in DynamoDB (Amazon Web Services). I read the first CSV, store each header in a Dict.
CSV #1 -> I have 3 Dicts (Country Name, Language, ISO3). Country Name is the PRIMARY KEY in my DynamoDb table.
CSV #2 -> I only want to store 1 column from the CSV so I have only 1 Dict (Area).
When I upload the values, it does not loop through every value in Area, like it does for the 3 dicts in CSV 1.
with open('shortlist_languages.csv', 'r') as file:
reader = csv.DictReader(file)
for row in reader:
country_name = {
'Country Name': row['Country Name']
}
languages = {
'Languages': row['Languages']
}
iso3 = {
'ISO3': row['ISO3']
}
with open('shortlist_area.csv', 'r') as file_area:
reader_area = csv.DictReader(file_area)
for row in reader_area:
area = {
'Area': row['Area']
}
for vals_area in area.values():
for value in country_name.values():
print(value)
for values in languages.values():
for values_iso3 in iso3.values():
with table.batch_writer(overwrite_by_pkeys=['Country Name']) as batch:
batch.put_item(
Item={
'Country Name': value,
'Languages': values,
'ISO3': values_iso3,
'Area':vals_area
}
)
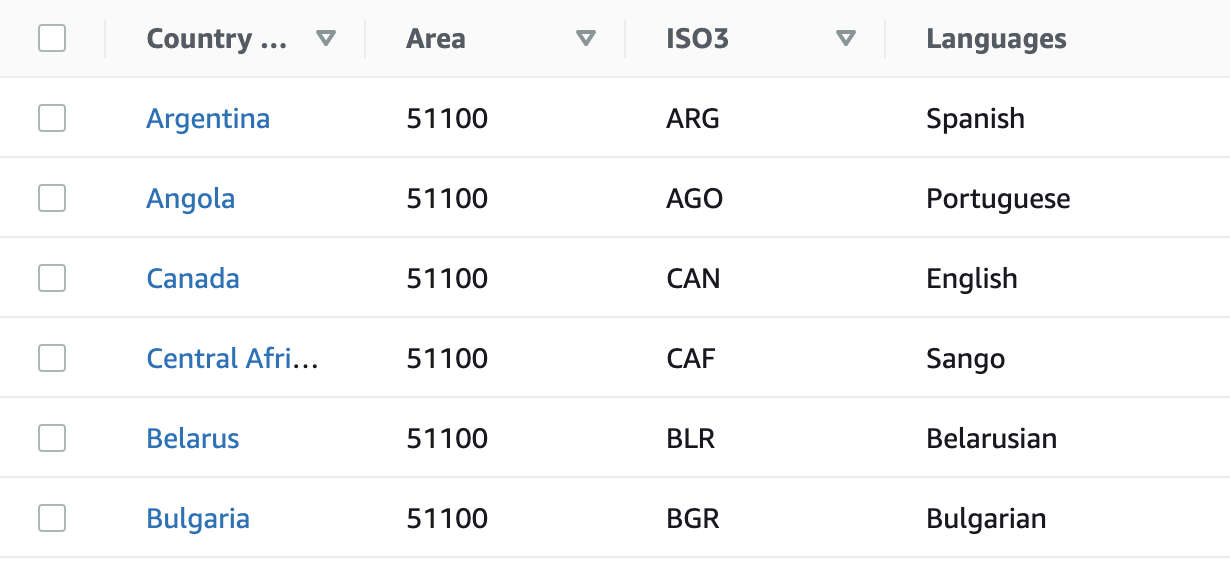
Screenshot of my DynamoDB table--as you can see Area is not looping properly. The last value of Area in my CSV is repeatedly printing. How can i fix that?
CSV#1 Sample:
ISO3,Country Name,Languages
ALB,Albania,Albanian
DZA,Algeria,Arabic,Tamazight
AND,Andorra,Catalan
AGO,Angola,Portuguese
CSV #2 Sample
ISO3,Country Name,Area
ALB,Albania,28748
DZA,Algeria,2381741
AND,Andorra,468
AGO,Angola,1246700
CodePudding user response:
Your code is nested incorrectly. Here is some example code that first reads the languages file into a dictionary, then loops through the area file:
languages = {}
table = []
# Load languages, catering for multiple languages
with open('shortlist_languages.csv') as languages_file:
for line in languages_file:
fields = line.strip().split(',')
languages[fields[0]] = ','.join(fields[2:])
# Load countries
with open('shortlist_area.csv') as countries_file:
for line in countries_file:
fields = line.strip().split(',')
table.append(
{
'Country Name': fields[1],
'Languages': languages[fields[0]],
'ISO3': fields[0],
'Area': fields[2]
}
)
print(table)
(I was too lazy to use the CSV functions!)
The output is:
[
{
"Country Name": "Country Name",
"Languages": "Languages",
"ISO3": "ISO3",
"Area": "Area"
},
{
"Country Name": "Albania",
"Languages": "Albanian",
"ISO3": "ALB",
"Area": "28748"
},
{
"Country Name": "Algeria",
"Languages": "Arabic,Tamazight",
"ISO3": "DZA",
"Area": "2381741"
},
{
"Country Name": "Andorra",
"Languages": "Catalan",
"ISO3": "AND",
"Area": "468"
},
{
"Country Name": "Angola",
"Languages": "Portuguese",
"ISO3": "AGO",
"Area": "1246700"
}
]
Note that Algeria has multiple languages in its output.