Say I have this DataFrame:
| user | sub_date | unsub_date | group | |
|---|---|---|---|---|
| 0 | alice | 2021-01-01 00:00:00 | 2021-02-09 00:00:00 | A |
| 1 | bob | 2021-02-03 00:00:00 | 2021-04-05 00:00:00 | B |
| 2 | charlie | 2021-02-03 00:00:00 | NaT | A |
| 3 | dave | 2021-01-29 00:00:00 | 2021-09-01 00:00:00 | B |
What is the most efficient way to count the subbed users per date and per group? In other words, to get this DataFrame:
| date | group | subbed |
|---|---|---|
| 2021-01-01 | A | 1 |
| 2021-01-01 | B | 0 |
| 2021-01-02 | A | 1 |
| 2021-01-02 | B | 0 |
| ... | ... | ... |
| 2021-02-03 | A | 2 |
| 2021-02-03 | B | 2 |
| ... | ... | ... |
| 2021-02-10 | A | 1 |
| 2021-02-10 | B | 2 |
| ... | ... | ... |
Here's a snippet to init the example df:
import pandas as pd
import datetime as dt
users = pd.DataFrame(
[
["alice", "2021-01-01", "2021-02-09", "A"],
["bob", "2021-02-03", "2021-04-05", "B"],
["charlie", "2021-02-03", None, "A"],
["dave", "2021-01-29", "2021-09-01", "B"],
],
columns=["user", "sub_date", "unsub_date", "group"],
)
users[["sub_date", "unsub_date"]] = users[["sub_date", "unsub_date"]].apply(
pd.to_datetime
)
CodePudding user response:
Using a smaller date range for convenience
Note: my users df is different from OPs. I've changed around a few dates to make the outputs smaller
In [26]: import pandas as pd
...: import datetime as dt
...:
...: users = pd.DataFrame(
...: [
...: ["alice", "2021-01-01", "2021-01-05", "A"],
...: ["bob", "2021-01-03", "2021-01-07", "B"],
...: ["charlie", "2021-01-03", None, "A"],
...: ["dave", "2021-01-09", "2021-01-11", "B"],
...: ],
...: columns=["user", "sub_date", "unsub_date", "group"],
...: )
...:
...: users[["sub_date", "unsub_date"]] = users[["sub_date", "unsub_date"]].apply(
...: pd.to_datetime
...: )
In [81]: users
Out[81]:
user sub_date unsub_date group
0 alice 2021-01-01 2021-01-05 A
1 bob 2021-01-03 2021-01-07 B
2 charlie 2021-01-03 NaT A
3 dave 2021-01-09 2021-01-11 B
In [82]: users.melt(id_vars=['user', 'group'])
Out[82]:
user group variable value
0 alice A sub_date 2021-01-01
1 bob B sub_date 2021-01-03
2 charlie A sub_date 2021-01-03
3 dave B sub_date 2021-01-09
4 alice A unsub_date 2021-01-05
5 bob B unsub_date 2021-01-07
6 charlie A unsub_date NaT
7 dave B unsub_date 2021-01-11
# dropna to remove rows with no unsub_date
# sort_values to sort by date
# sub_date exists -> map to 1, else -1 then take cumsum to get # of subbed people at that date
In [85]: melted = users.melt(id_vars=['user', 'group']).dropna().sort_values('value')
...: melted['sub_value'] = np.where(melted['variable'] == 'sub_date', 1, -1) # or melted['variable'].map({'sub_date': 1, 'unsub_date': -1})
...: melted['sub_cumsum_group'] = melted.groupby('group')['sub_value'].cumsum()
...: melted
Out[85]:
user group variable value sub_value sub_cumsum_group
0 alice A sub_date 2021-01-01 1 1
1 bob B sub_date 2021-01-03 1 1
2 charlie A sub_date 2021-01-03 1 2
4 alice A unsub_date 2021-01-05 -1 1
5 bob B unsub_date 2021-01-07 -1 0
3 dave B sub_date 2021-01-09 1 1
7 dave B unsub_date 2021-01-11 -1 0
In [93]: idx = pd.date_range(melted['value'].min(), melted['value'].max(), freq='1D')
...: idx
Out[93]:
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
'2021-01-09', '2021-01-10', '2021-01-11'],
dtype='datetime64[ns]', freq='D')
In [94]: melted.set_index('value').groupby('group')['sub_cumsum_group'].apply(lambda x: x.reindex(idx).ffill().fillna(0))
Out[94]:
group
A 2021-01-01 1.0
2021-01-02 1.0
2021-01-03 2.0
2021-01-04 2.0
2021-01-05 1.0
2021-01-06 1.0
2021-01-07 1.0
2021-01-08 1.0
2021-01-09 1.0
2021-01-10 1.0
2021-01-11 1.0
B 2021-01-01 0.0
2021-01-02 0.0
2021-01-03 1.0
2021-01-04 1.0
2021-01-05 1.0
2021-01-06 1.0
2021-01-07 0.0
2021-01-08 0.0
2021-01-09 1.0
2021-01-10 1.0
2021-01-11 0.0
Name: sub_cumsum_group, dtype: float64
CodePudding user response:
Try this?
>>> users.groupby(['sub_date','group'])[['user']].count()
CodePudding user response:
The data is described by step functions, and 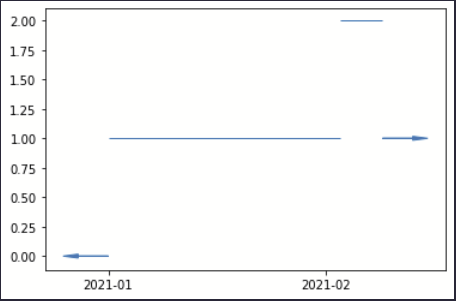
Next step is to sample the step function at whatever dates you want, eg for every day of January..
sc.sample(stepfunctions, pd.date_range("2021-01-01", "2021-02-01")).melt(ignore_index=False).reset_index()
The result is this
group variable value
0 A 2021-01-01 1
1 B 2021-01-01 0
2 A 2021-01-02 1
3 B 2021-01-02 0
4 A 2021-01-03 1
.. ... ... ...
59 B 2021-01-30 1
60 A 2021-01-31 1
61 B 2021-01-31 1
62 A 2021-02-01 1
63 B 2021-02-01 1