I have a pandas dataframe with lets say two columns, for example:
value boolean
0 1 0
1 5 1
2 0 0
3 3 0
4 9 1
5 12 0
6 4 0
7 7 1
8 8 1
9 2 0
10 17 0
11 15 1
12 6 0
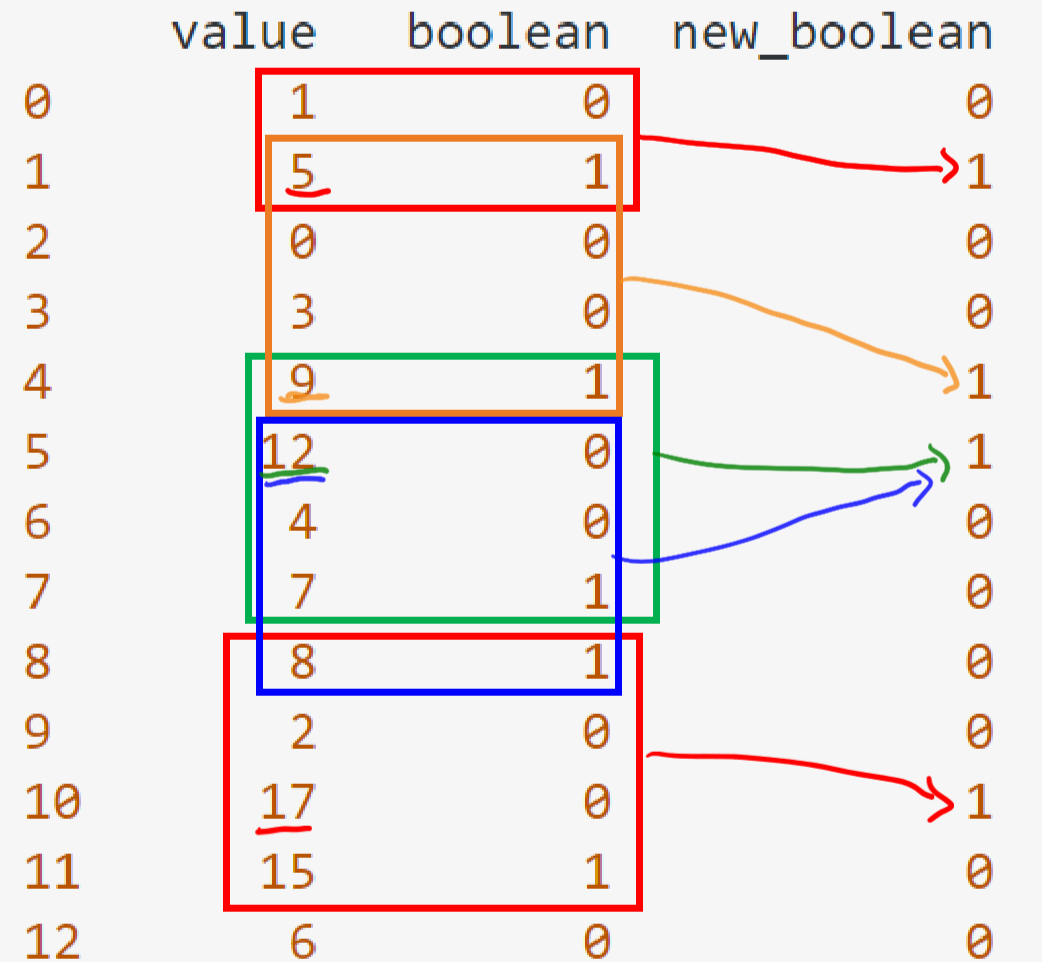
Now I want to add a third column (new_boolean) with the following criteria: I specify a period, for this example period = 4. Now I take a look at all rows where boolean == 1. new_boolean will be 1 for the maximum value in the last period rows.
For example I have boolean == 1 for row 2. So I look at the last period rows. The values are [1, 5], 5 is the maximum, so the value for new_boolean in row 2 will be one.
Second example: row 8 (value = 7): I get values [7, 4, 12, 9], 12 is the maximum, so the value for new_boolean in the row with value 12 will be 1
result:
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
How can I do this algorithmically?
CodePudding user response:
Use df.index with df.iloc and df.idxmax:
In [182]: period = 4 # Define period to 4
In [183]: ix = df[df.boolean.eq(1)].index # Create a list of indexes where boolean = 1
In [213]: new_bool_ix = [] # empty list
# For every index in `ix`, take the last 4 rows and append the index of maximum `value`
In [215]: for i in ix:
...: new_bool_ix.append(df.iloc[:i 1].iloc[-period:]['value'].idxmax())
...:
In [225]: df['new_boolean'] = 0 # declare column new_boolean with default value `0`
In [227]: df.loc[new_bool_ix, 'new_boolean'] = 1 # Change the value to 1 for the indexes in new_bool_ix
In [228]: df
Out[228]:
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
CodePudding user response:
Compute the rolling max of the 'value' column
>>> rolling_max_value = df.rolling(window=4, min_periods=1)['value'].max()
>>> rolling_max_value
0 1.0
1 5.0
2 5.0
3 5.0
4 9.0
5 12.0
6 12.0
7 12.0
8 12.0
9 8.0
10 17.0
11 17.0
12 17.0
Name: value, dtype: float64
Select only the relevant values, i.e. where 'boolean' = 1
>>> on_values = rolling_max_value[df.boolean == 1].unique()
>>> on_values
array([ 5., 9., 12., 17.])
The rows where 'new_boolean' = 1 are the ones where 'value' belongs to on_values
>>> df['new_boolean'] = df.value.isin(on_values).astype(int)
>>> df
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
EDIT:
OP raised a good point
Does this also work if I have multiple columns with the same value and they have different booleans?
The previous solution doesn't account for that. To solve this, instead of computing the rolling max, we gather the row labels associated with rolling max values, i.e. the rolling argmaxor idxmax. To my knowledge, Rolling objects don't have an idxmax method, but we can easily compute it via apply.
def idxmax(values):
return values.idxmax()
rolling_idxmax_value = (
df.rolling(min_periods=1, window=4)['value']
.apply(idxmax)
.astype(int)
)
on_idx = rolling_idxmax_value[df.boolean == 1].unique()
df['new_boolean'] = 0
df.loc[on_idx, 'new_boolean'] = 1
Results:
>>> rolling_idxmax_value
0 0
1 1
2 1
3 1
4 4
5 5
6 5
7 5
8 5
9 8
10 10
11 10
12 10
Name: value, dtype: int64
>>> on_idx
[ 1 4 5 10]
>>> df
value boolean new_boolean
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 1
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 1
11 15 1 0
12 6 0 0
CodePudding user response:
I did this in 2 steps, but I think the solution is much clearer:
df = pd.read_csv(StringIO('''
id value boolean
0 1 0
1 5 1
2 0 0
3 3 0
4 9 1
5 12 0
6 4 0
7 7 1
8 8 1
9 2 0
10 17 0
11 15 1
12 6 0'''),delim_whitespace=True,index_col=0)
df['new_bool'] = df['value'].rolling(min_periods=1, window=4).max()
df['new_bool'] = df.apply(lambda x: 1 if ((x['value'] == x['new_bool']) & (x['boolean'] == 1)) else 0, axis=1)
df
Result:
value boolean new_bool
id
0 1 0 0
1 5 1 1
2 0 0 0
3 3 0 0
4 9 1 1
5 12 0 0
6 4 0 0
7 7 1 0
8 8 1 0
9 2 0 0
10 17 0 0
11 15 1 0
12 6 0 0