I have these four lists, which are the filenames of images and the filenames are in the format:
(disease)-(randomized patient ID)-(image number by this patient)
A single patient can have multiple images per disease.
See these slices below:
print(train_cnv_list[0:3])
print(train_dme_list[0:3])
print(train_drusen_list[0:3])
print(train_normal_list[0:3])
>>>
['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
I'd like to figure out:
- How many images are there per patient / per list?
- Is there any overlap in the "randomized patient ID" across the four lists? If so, can I aggregate that into some kind of report (patient, disease, number of images) using something like groupby?
patient - disease1 - total number of images
- disease2 - total number of images
- disease3 - total number of images
where total number of images is a max(image number by this patient)
I did see that this yields a patient id:
train_cnv_list[0][4:11]
>>> 9911627
Thanks, in advance, for any guidance.
CodePudding user response:
You can do it easily with Pandas:
import pandas as pd
cnv_list=['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
dme_list=['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
dru_list=['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
nor_list=['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
data =[]
data.extend(cnv_list)
data.extend(dme_list)
data.extend(dru_list)
data.extend(nor_list)
df = pd.DataFrame(data, columns=["files"])
df["files"]=df["files"].str.replace ('.jpeg','')
df=df["files"].str.split('-', expand=True).rename(columns={0:"disease",1:"PatientID",2:"pictureName"})
res = df.groupby(['PatientID','disease']).apply(lambda x: x['pictureName'].count())
print(res)
Result:
PatientID disease
8773471 DME 1
8797076 DME 1
8889850 DME 1
8986660 DRUSEN 1
9025088 DRUSEN 1
9100857 DRUSEN 1
9490249 NORMAL 1
9504376 NORMAL 1
9509694 NORMAL 1
9911627 CNV 2
9935363 CNV 1
and even more now than you have a dataFrame...
CodePudding user response:
Here are a few functions that might get you on the right track, but as @rick-supports-monica mentioned, this is a great use case for pandas. You'll have an easier time manipulating data.
def contains_duplicate_ids(img_list):
patient_ids = []
for image in img_list:
patient_id = image.split('.')[0].split('-')[1]
patient_ids.append(patient_id)
if len(set(patient_ids)) == len(patient_ids):
return False
return True
def get_duplicates(img_list):
patient_ids = []
duplicates = []
for image in img_list:
patient_id = image.split('.')[0].split('-')[1]
if patient_id in patient_ids:
duplicates.append(patient_id)
patient_ids.append(patient_id)
return duplicates
def count_images(img_list):
return len(set(img_list))
From get_duplicates you can use the patient IDs returned to lookup whatever you want from there. I'm not sure I completely understand the structure of the lists. It looks like {disease}-{patient_id}-{some_other_int}.jpg. I'm not sure how to add additional lookups to the functionality without understanding the input a bit more.
I mentioned pandas, but didn't mention how to use it, here's one way you could get your existing data into a dataframe:
import pandas as pd
# Sample data
train_cnv_list = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911628-94.jpeg', 'CNM-9911629-94.jpeg']
train_dme_list = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
train_drusen_list = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
train_normal_list = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
# Convert list to dataframe
def dataframe_from_list(img_list):
df = pd.DataFrame(img_list, columns=['filename'])
df['disease'] = [filename.split('.')[0].split('-')[0] for filename in img_list]
df['patient_id'] = [filename.split('.')[0].split('-')[1] for filename in img_list]
df['some_other_int'] = [filename.split('.')[0].split('-')[2] for filename in img_list]
return df
# Generate a dataframe for each list
cnv_df = dataframe_from_list(train_cnv_list)
dme_df = dataframe_from_list(train_dme_list)
drusen_df = dataframe_from_list(train_drusen_list)
normal_df = dataframe_from_list(train_normal_list)
# or combine them into one long dataframe
df = pd.concat([cnv_df, dme_df, drusen_df, normal_df], ignore_index=True)
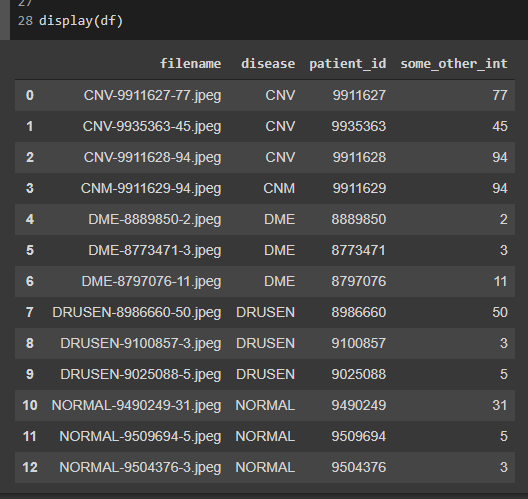
CodePudding user response:
Start by creating a well defined data structure, use counter in order to answer your first question.
from typing import NamedTuple
from collections import Counter,defaultdict
class FileInfo(NamedTuple):
disease:str
patient_id:str
image_id: str
l1 = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
l2 = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
l3 = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
l4 = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
lists = [l1,l2,l3,l4]
data_lists = []
for l in lists:
data_lists.append([FileInfo(*f[:-5].split('-')) for f in l])
counters = []
for l in data_lists:
counters.append(Counter(fi.patient_id for fi in l))
print(counters)
print('-----------')
cross_lists_data = dict()
for l in data_lists:
for file_info in l:
if file_info.patient_id not in cross_lists_data:
cross_lists_data[file_info.patient_id] = defaultdict(int)
cross_lists_data[file_info.patient_id][file_info.disease] = 1
print(cross_lists_data)
CodePudding user response:
Start by concatenating your data
import pandas as pd
import numpy as np
train_cnv_list = ['CNV-9911627-77.jpeg', 'CNV-9935363-45.jpeg', 'CNV-9911627-94.jpeg']
train_dme_list = ['DME-8889850-2.jpeg', 'DME-8773471-3.jpeg', 'DME-8797076-11.jpeg']
train_drusen_list = ['DRUSEN-8986660-50.jpeg', 'DRUSEN-9100857-3.jpeg', 'DRUSEN-9025088-5.jpeg']
train_normal_list = ['NORMAL-9490249-31.jpeg', 'NORMAL-9509694-5.jpeg', 'NORMAL-9504376-3.jpeg']
train_data = np.array([
train_cnv_list,
train_dme_list,
train_drusen_list,
train_normal_list
])
Create a Series with the flattened array
>>> train = pd.Series(train_data.flat)
>>> train
0 CNV-9911627-77.jpeg
1 CNV-9935363-45.jpeg
2 CNV-9911627-94.jpeg
3 DME-8889850-2.jpeg
4 DME-8773471-3.jpeg
5 DME-8797076-11.jpeg
6 DRUSEN-8986660-50.jpeg
7 DRUSEN-9100857-3.jpeg
8 DRUSEN-9025088-5.jpeg
9 NORMAL-9490249-31.jpeg
10 NORMAL-9509694-5.jpeg
11 NORMAL-9504376-3.jpeg
dtype: object
Use Series.str.extract together with regex to extract the information from the filenames and separate it into different columns
>>> pat = '(?P<Disease>\w )-(?P<Patient_ID>\d )-(?P<IMG_ID>\d ).jpeg'
>>> train = train.str.extract(pat)
>>> train
Disease Patient_ID IMG_ID
0 CNV 9911627 77
1 CNV 9935363 45
2 CNV 9911627 94
3 DME 8889850 2
4 DME 8773471 3
5 DME 8797076 11
6 DRUSEN 8986660 50
7 DRUSEN 9100857 3
8 DRUSEN 9025088 5
9 NORMAL 9490249 31
10 NORMAL 9509694 5
11 NORMAL 9504376 3
Finally, aggregate the data and compute the total number of images per group based on the maximum IMG_ID number.
>>> report = train.groupby(["Patient_ID","Disease"])['IMG_ID'].agg(Total_IMGs="max")
>>> report
Total_IMGs
Patient_ID Disease
8773471 DME 3
8797076 DME 11
8889850 DME 2
8986660 DRUSEN 50
9025088 DRUSEN 5
9100857 DRUSEN 3
9490249 NORMAL 31
9504376 NORMAL 3
9509694 NORMAL 5
9911627 CNV 94
9935363 CNV 45